import numpy as np
import torch as th
import torch.nn as nn
import matplotlib.pyplot as pltDiffusion Models
To create incredibly lifelike and beautiful images and videos, you no longer need a camera, you don’t need to know how to draw or how to paint. All you need is language.
在机器学习领域,扩散模型(diffusion model, diffusion-based generative models, score-based generative models)是一类潜变量生成模型 (latent variable generative models)。它起源于 GAN 和 VAE 的研究,由两个主要组件构成:前向扩散过程和反向采样过程。
扩散模型的目标是为给定数据集学习一个扩散过程,使得该过程能够生成与原始数据集分布相似的新数据。扩散模型将数据建模为由扩散过程生成,其中新数据通过带漂移的随机游走在所有可能数据空间中进行演化。训练完成的扩散模型可通过多种方式进行采样,其效率与质量各有不同。
数学前置: Variational Inference
Variational Bayesion Methods
本小节介绍了变分推断的基本概念和数学背景。不同于神经网络,变分推断是传统统计学习的延伸,旨在通过优化方法来近似计算复杂的概率分布。变分推断的核心思想是将复杂的后验分布转化为一个更简单的分布,并通过优化来最小化这两个分布之间的差异。
Glossary
- \(\mathbf{X}\): 给定的数据
- \(\mathbf{Z}\): 潜变量
- \(P(Z|X)\): 在给定数据 \(\mathbf{X}\) 的情况下,潜变量 \(\mathbf{Z}\) 的后验分布
- \(G(\theta)\): 以 \(\theta\) 为待定参数的 Generative Model
变分目标和 KL 散度
一般来讲,生成模型的目标是,将一个已知的分布(通常是简单的分布,如高斯分布)映射到一个复杂的分布(如图像数据分布)。
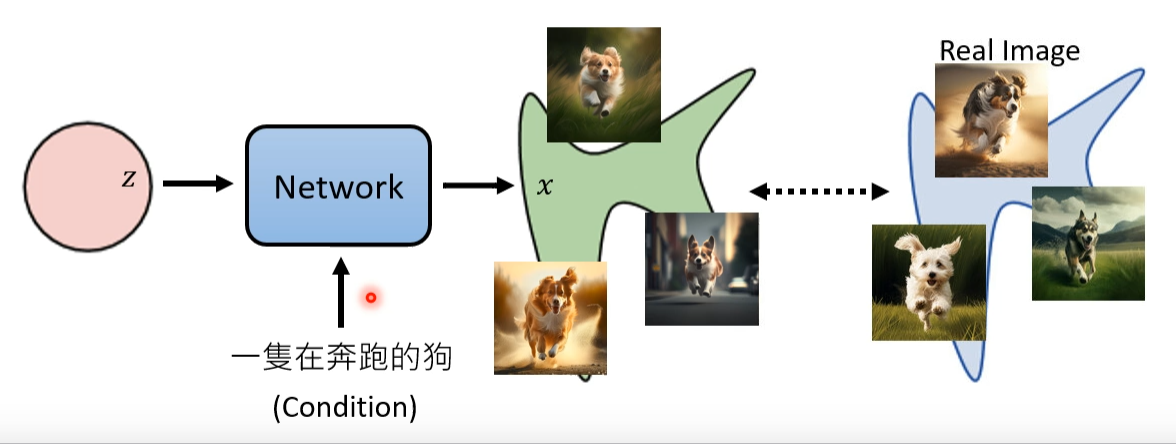
对于一个 \(z \sim \pi (z)\),我们通过一个 generator \(G\) 来生成一个样本 \(x = G(z)\),其中 \(x\) 满足一个新的分布 \(p_G(x)\). 现在,我们需要让 generator 生成的样本 \(x\) 的分布 \(p_G(x)\) 尽可能接近真实数据分布 \(p_{data}(x)\). 简单来说,就是最大似然函数法(Maximum likelihood estimation, MLE):
\[ G^* = \arg \max L \equiv \arg \max \sum_{i=1}^{m} \log P_G(x_i) \]
从训练的角度来说,我们也可以这么理解:
在变分推断中,给定数据 \(\displaystyle \mathbf {X} \sim P_{data}(X)\) 时,一组未观测变量 \({\displaystyle \mathbf {Z}}\) 的后验分布通过所谓的变分分布 \({\displaystyle Q(\mathbf {Z} )}\) 来近似: \[P(Z | X) \approx Q(Z)\]
为什么作此近似?因为由于贝叶斯定理: \[P(Z | X) = \frac{P(X|Z)P(Z)}{P(X)} = \frac{P(X|Z)P(Z)}{\int P(X, Z') d Z'}\] 中 \({Z}\) 的后验分布通常是不可解的,或者计算代价过高。于是,我们要求使用该近似。 \({\displaystyle Q(\mathbf {Z} )}\) 被限制属于比 \({\displaystyle P(\mathbf {Z} \mid \mathbf {X} )}\) 形式更简单的分布族(例如高斯分布族), 选择目的是使 \({\displaystyle Q(\mathbf {Z} )}\) 接近真实后验 \({\displaystyle P(\mathbf {Z} \mid \mathbf {X} )}\). 通过令 dissimilarity function \(d(Q|P)\) 最小化来实现近似.
在这里,我们很难直接计算 \(P_G(x_i)\),因为这样就要遍历 \(Z\), 因此作一个 math trick: 假设我们的 \(x\) 足够多使得 \(x_i \sim P_{data}\), 那么我们可以将上式近似为:
\[ \begin{align*} G^* &= \arg \max_\theta \sum_{i=1}^{m} \log P_{G(\theta)}(x_i) &\\ & \approx \arg \max_\theta \mathbb{E}_{x \sim P_{data} } \log P_{G(\theta)}(x_i) & (x_i \sim P_{data}(x))\\ & = \arg \max_\theta \int P_{data}(x) \log P_{G(\theta)}(x) dx &\\ & = \arg \max_\theta \int P_{data}(x) \log P_{G(\theta)}(x) dx - \int P_{data}(x) \log P_{data}(x) dx & (\text{2nd term don't have } \theta)\\ & = \arg \max_\theta \int P_{data}(x) \log \frac{P_{G(\theta)}(x)}{P_{data}(x)} dx &\\ & = \arg \min_\theta KL(P_{data}(x) || P_{G(\theta)}(x)) &\\ \end{align*} \]
在这里,\(KL(P||Q)\) 是 KL 散度 (Kullback-Leibler divergence),用于衡量两个概率分布之间的差异。KL 散度的定义为 \[D_{KL}(Q||P) = \int Q(Z) \log \frac{Q(Z)}{P(Z)} dZ \quad (>0)\]
综上,我们得到: 最大化似然函数和最小化 KL 散度是等价的。
\[ \begin{align*} G^* &= \arg \max_\theta \sum_{i=1}^{m} \log P_{G(\theta)}(x_i) &\\ & \approx \arg \max_\theta \mathbb{E}_{x \sim P_{data} } \log P_{G(\theta)}(x_i) & (x_i \sim P_{data}(x))\\ & = \arg \max_\theta \int P_{data}(x) \log P_{G(\theta)}(x) dx &\\ & = \arg \max_\theta \int P_{data}(x) \log P_{G(\theta)}(x) dx - \int P_{data}(x) \log P_{data}(x) dx & (\text{2nd term don't have } \theta)\\ & = \arg \max_\theta \int P_{data}(x) \log \frac{P_{G(\theta)}(x)}{P_{data}(x)} dx &\\ & = \arg \min_\theta KL(P_{data}(x) || P_{G(\theta)}(x)) &\\ \end{align*} \]
在这里,\(KL(P||Q)\) 是 KL 散度 (Kullback-Leibler divergence),用于衡量两个概率分布之间的差异。KL 散度的定义为 \[D_{KL}(Q||P) = \int Q(Z) \log \frac{Q(Z)}{P(Z)} dZ \quad (>0)\]
综上,我们得到:最大化似然函数和最小化 KL 散度是等价的。
Gaussian Prior
以下简写 \(P_{G(\theta)}(x)\) 为 \(P_\theta(x)\).
接上面的 KL 散度,如果我们要计算 \(P_\theta(x)\),先要使用 marginal distribution \(z \sim \pi(z)\) : \[P_\theta(x) = \int P(z) P_\theta(x|z) dz\]
理论上 \(P_\theta(x|z)\) 是一个 \(\delta\) 函数,然而在实际应用中,我们通常使用一个高斯分布来近似它。这样,我们可以将 \(P_\theta(x|z)\) 写成一个高斯分布的形式:
\[ \begin{align*} P_\theta(x|z) & \propto \exp\left(-\frac{1}{2\sigma^2} ||x - G(z, \theta)||^2\right) \\ &= \mathcal{N}(x; G(z, \theta), \sigma^2 I) \end{align*} \]
在这里,\(\sigma\) 的大小可以近似看成分辨率的大小.
Evidence Lower Bound (ELBO)
ELBO 是 Evidence Lower Bound(证据下界)的缩写。
对于给定的观测数据 \(\mathbf{X}\) 和潜在变量 \(\mathbf{Z}\),我们希望最大化对数边际似然 \(\log P(\mathbf{X}) = \log \int P(\mathbf{X}, \mathbf{Z}) d\mathbf{Z}\). 通过引入变分分布 \(Q(\mathbf{Z})\),我们可以将对数边际似然重写为:
\[ \log P(\mathbf{X}) = D_{KL} (Q||P) + \mathbb{E}_Q [\log \frac{Q(Z)}{P(Z, X)}] \]
\[ \begin{align*} D_{KL} (Q||P) &= \sum_Z Q(Z) [\log \frac{Q(Z)}{P(Z,X)} + \log P(X)] , &(\text{Beyes Formula}) \\ &= \sum_Z Q(Z) [\log Q(Z) - \log P(Z, X)] + \sum_Z Q(Z) \log P(X) &\\ &= \sum_Z Q(Z) [\log Q(Z) - \log P(Z, X)] + \log P(X) , & (\sum_Z Q(Z) = 1)\\ &= \mathbb{E}_Q [\log Q(Z) - \log P(Z, X)] + \log P(X), & (\text{Expectation}) \end{align*} \]
由于 KL 散度总是非负的,我们得到:
\[ \log P(\mathbf{X}) \geq \mathbb{E}_{Q(\mathbf{Z})} \left[ \log \frac{P(\mathbf{X}, \mathbf{Z})}{Q(\mathbf{Z})} \right] \equiv \mathcal{L}(Q) \]
这一项就是 ELBO.
由于 \(\log P(X)\) 是一个常数,我们可以将其忽略,因此最大化 ELBO 等价于最小化 KL 散度。\(\mathcal{L(Q)}\) 也被称作 Variational Free Energy,因为它也可以表示为负能量加上熵。
DDPM
DDPM(Denoising Diffusion Probabilistic Models)是一种基于扩散过程的生成模型,其核心思想是通过逐步添加噪声来破坏数据,然后学习逆向过程来生成新数据。最”玄学”的地方在于,在采样过程中,DDPM 加入了随机的噪声来生成新数据,这个过程类似于物理学中的扩散现象。
Notations
- \(q\): the diffusion process distribution.
- \(p\): the reverse process distribution.
- \(\beta_1, \ldots, \beta_T \in (0,1)\) are Fixed constants .
- \(\alpha_t := 1 - \beta_t\)
- \(\bar{\alpha}_t := \prod_{s=1}^t \alpha_s\) : Cumulative product of \(\alpha_s\)
- \(\sigma_t := \sqrt{1 - \bar{\alpha}_t}\) : Standard deviation at time \(t\)
- \(\tilde{\sigma}_t := \frac{\sigma_{t-1}}{\sigma_t}\sqrt{\beta_t}\) : Adjusted standard deviation
- \(\tilde{\mu}_t(\mathbf{x}_t, \mathbf{x}_0) := \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})\mathbf{x}_t + \sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)\mathbf{x}_0}{\sigma_t^2}\) : Posterior mean
- \(\mathcal{N}(\mu, \Sigma)\) : Normal distribution with mean \(\mu\) and variance \(\Sigma\), while \(\mathcal{N}(\mathbf{x} \mid \mu, \Sigma)\) is probability density at \(\mathbf{x}\) for normal distribution.
模型结构与优化目标
不同于 VAE 中 Generator 的目标是从一个简单先验分布生成样本分布,DDPM 的目标是学习样本分布到简单先验分布的映射,或者说,Generator 是在学习噪声 \(\varepsilon\) !
我们先定义以下两个过程:
- forward process: 从目标 \(x_0\) 开始经历 T 步 noise 到噪声 \(x_T\) 的过程 \(q(x_t | x_{t-1})\)
- reverse process: 从噪声 \(x_T\) 开始经历 T 步 denoise 回目标 \(x_0\) 的过程 \(p_\theta(x_{t-1} | x_t)\)
- VAE 中的 q 是 encoder,对应 DDPM 中的 forward process \(q\); VAE 中的 \(G\) 是 decoder,对应 DDPM 中的 reverse process \(p\).
- 在 DDPM 的论文中,q 过程的参数是指定的,为非学习量。因此,DDPM 含有非常强的网络先验.
p 过程的 markov 链定义了 marginal 依赖: \[ p_\theta(x_0) = p(x_T) \prod_{t=1}^T p_\theta(x_{t-1} | x_t) \]
同样定义了 q 的 markov 链: \[ q(\mathbf{x}_{1:T} | \mathbf{x}_0) := \prod_{t=1}^T q(\mathbf{x}_t | \mathbf{x}_{t-1}) \]
我们引用一下 VAE 中推导的似然函数的结论:
\[ \begin{align*} G* &= \arg \max \sum_{i=1}^{m} \log P_G(x_i) \\ & \approx \arg \max_\theta \int P_{data}(x) \log \frac{P_{G(\theta)}(x)}{P_{data}(x)} dx \\ & = \arg \max_\theta \mathbb{E}_{x \sim P_{data}} \left[ \log \frac{P_{G(\theta)}(x)}{P_{data}(x)} \right] \\ \end{align*} \]
与前面的理论分析中的从 Gaussian 开始“扩散”不同,DDPM 的前向扩散过程是基于数据的扩散,即逐步添加噪声直到一个近似于高斯分布的样本。因此,这里的 \(P_{data}(x)\) 替换为 \(q\), \(P_{G(\theta)}(x)\) 替换为 \(p\). 带入似然函数得到 DDPM 的优化目标:
\[ \text{Maximize } \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ \log \left( \frac{P(x_0:x_T)}{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \right) \right] \]
Forward Process
前向扩散过程从 \(\mathbf{x}_0 \sim q\) 开始,其中 \(q\) 分布需要学习参数 \(\theta\)。 逐步添加噪声来破坏数据(论文中的定义):
\[ \mathbf{x}_t = \sqrt{\alpha_t} \mathbf{x}_{t-1} + \sqrt{\beta_t} \mathbf{z}_t, \quad \alpha_t := 1 - \beta_t \]
其中 \(\mathbf{z}_1, \ldots, \mathbf{z}_T \sim \mathcal{N}(0, I)\). 这里 \(\{\beta_t\}_{t=1}^T\) 是预定义的噪声调度(noise schedule)。
代入 markov 链得到
\[ q(x_{0:T}) = q(x_0) \prod_{t=1}^T q(x_t | x_{t-1}) = q(x_0) \prod_{t=1}^T \mathcal{N}(x_t; \sqrt{\alpha_t} x_{t-1}, \beta_t I) \]
这样虽然可以得到 q 的分布,但是要经历 t 次迭代,好在正向扩散中除了要学习的参数全是可以常数,于是我们可以使用 reparametrization trick 来直接获得 \(\mathbf{x}_t | \mathbf{x}_0\):
Reparametrization Trick
由 \(x_1 = \sqrt{\alpha_1} x_0 + \sqrt{\beta_1} z_1, \, x_2 = \sqrt{\alpha_2} x_1 + \sqrt{\beta_2} z_2\), 得
\[ \begin{align*} x_2 &= \sqrt{\alpha_2} (\sqrt{\alpha_1} x_0 + \sqrt{\beta_1} z_1) + \sqrt{\beta_2} z_2 \\ &= \sqrt{\alpha_1 \alpha_2} x_0 + (\sqrt{\alpha_2} \sqrt{\beta_1} z_1 + \sqrt{\beta_2} z_2) \\ \end{align*} \]
由于 \(z_i \sim \mathcal{N(0, I)}\), 我们可以将其重参数化为:
\[ \begin{align*} \sqrt{\alpha_2} \sqrt{\beta_1} z_1 + \sqrt{\beta_2} z_2 &= \sqrt{\alpha_2 \beta_1 + \beta_2} z \\ &= \sqrt{1 - \alpha_1 \alpha_2} z \end{align*} \]
即为 \[ x_2 | x_0 \sim \mathcal{N}(\sqrt{\overline{\alpha}_2} x_0, \sigma_2^2 I) \]
其中 \(\overline{\alpha}_t = \prod_{s=1}^t \alpha_s\) 是 \(\alpha_t\) 的累积乘积,\(\sigma_t = \sqrt{1 - \overline{\alpha}_t}\) 是标准差。 由数学归纳法,我们可以得到:
\[ x_t | x_0 \sim \mathcal{N}(\sqrt{\overline{\alpha}_t} x_0, \sigma_t^2 I) \]
于是,我们可以一步到位采样 \(x_t | x_0\):
\[ q(\mathbf{x}_t | \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t}\mathbf{x}_0, (1-\bar{\alpha}_t)\mathbf{I}) \]
这样的设计下,当 \(t\) 趋近于无穷大时,\(\mathbf{x}_t | \mathbf{x}_0\) 的分布可以收敛到 \(\mathcal{N}(0, I)\)。
Reverse Process
反向过程是一个参数化的马尔可夫链,用神经网络 \(p_\theta\) 来近似:
\[p_\theta(\mathbf{x}_{0:T}) := p(\mathbf{x}_T) \prod_{t=1}^T p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)\]
其中:
\[p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t) := \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \Sigma_\theta(\mathbf{x}_t, t))\]
在这里,\(\mu, \Sigma\) 也包含 Forward Process 中的超参数.
在 reverse process 中,如果我们简单设置一个各向同性的参数,那么噪声将不可能收敛到目标分布。于是,我们需要一个神经网络来学习这个参数,这也是 diffusion model 的 essence. 接下来介绍 Denoise 神经网络是如何利用 forward process 的参数来学习 reverse process 的。
Connection with Forward Process
优化目标节中的函数并不能直接用于训练。我们可以将 \(q\) 和 \(p\) 的定义带入上式:
\[ \begin{align*} L &= - \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ \log \left( \frac{P(x_0:x_T)}{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \right) \right] \\ &= \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ - \log P(x_T) - \sum_{t \geq 1} \log \frac{p_\theta (x_{t-1} | x_t)}{q(x_{t}|x_{t-1})} \right] \\ &= \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ - \log P(x_T) - \sum_{t > 1} \log \frac{p_\theta (x_{t-1} | x_t)}{q(x_{t-1}|x_t, x_0)} \cdot \frac{q(x_{t-1}|x_0)}{q(x_t|x_0)} - \log \frac{p_\theta(x_0 | x_1)}{q(x_1 | x_0)} \right] \\ &= \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ - \log \frac{P(x_T)}{q(x_T|x_0)} - \sum_{t > 1} \log \frac{p_\theta (x_{t-1} | x_t)}{q(x_{t-1}|x_t, x_0)} - \log p_\theta(x_0 | x_1) - \sum_{t > 1} \log \frac{q(x_{t-1}|x_0)}{q(x_t|x_0)} \right] \\ &= \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ - \log \frac{P(x_T)}{q(x_T|x_0)} - \sum_{t > 1} \log \frac{p_\theta (x_{t-1} | x_t)}{q(x_{t-1}|x_t, x_0)} - \log p_\theta(x_0 | x_1) \right], \quad \text{(不包含 }\theta \text{, 舍去)} \\ \end{align*} \]
带入 KL 散度的定义得到:
\[ L = \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ D_{KL}(q(x_T|x_0) || P(x_T)) + \sum_{t > 1} D_{KL}(q(x_{t-1}|x_t, x_0) || p_\theta (x_{t-1} | x_t)) - \log p_\theta(x_0 | x_1) \right] \]
其中,第一项没有 \(\theta\),因此可以忽略。第二项是一个 KL 散度的和,表示了 \(q\) 和 \(p_\theta\) 之间的差异。第三项近似是一个常数项,可以忽略。因此,我们的目标是最小化级数求和的那一项:
\[ \text{Minimize } \sum_{t > 1} D_{KL}(q(x_{t-1}|x_t, x_0) || p_\theta (x_{t-1} | x_t)) \]
在这之中,\(p_\theta\) 是神经网络的输出,容易获得;比较难计算的是 \(q\).
回到 Forward Process,由 \(x_t = \sqrt{\overline{\alpha}_t} x_0 + \sigma_t \varepsilon\), \(x_{t-1} = \sqrt{\overline{\alpha}_{t-1}} x_0 + \sigma_{t-1} \varepsilon\),我们使用 reparametrization 得到 \[ q(x_{t}|x_{t-1}) = \mathcal{N}(\sqrt{1 - \beta_t} x_{t-1}, \beta_t I) \]
由 Bayes 公式,我们可以得到:
\[ \begin{align*} q(x_{t-1}|x_t, x_0) &= \frac{q(x_{t-1}, x_t, x_0)}{q(x_t, x_0)} \\ &= \frac{q(x_t | x_{t-1}, (x_0)) q(x_{t-1} | x_0) q(x_0)}{q(x_t | x_0) q(x_0)} \\ &= \frac{q(x_t | x_{t-1}) q(x_{t-1} | x_0)}{q(x_t | x_0)} \\ \end{align*} \]
经过繁琐的计算(arXiv),我们可以得到:
\[ q(x_{t-1}|x_t, x_0) = \mathcal{N}(\tilde{\mu}_t(x_t, x_0), \tilde{\sigma}_t^2 I) \]
其中 \(\tilde{\mu}_t(x_t, x_0) := \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})x_t + \sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)x_0}{\sigma_t^2}\) 是后验均值,\(\tilde{\sigma}_t := \frac{\sigma_{t-1}}{\sigma_t}\sqrt{\beta_t}\) 是调整后的标准差。
这样,我们通过似然函数的推导,得到了神经网络 \(p_\theta\) 与 \(q\) 的关联,这样我们就可以通过 q 来学习 \(p_\theta\) 了。
目标函数的简化
由于 \(p\) 和 \(q\) 都是高斯分布,因此 KL 散度可以进一步简化。
假设我们有两个多元正态分布 ,其均值分别为 \({\displaystyle \mu _{0},\mu _{1}}\) ,且具有(非奇异) 协方差矩阵 \({\displaystyle \Sigma _{0},\Sigma _{1}.}\) 。若两个分布具有相同的维度 k,则分布间的相对熵如下所示: \[ D_{\text{KL}}\left({\mathcal {N}}_{0}\parallel {\mathcal {N}}_{1}\right)={\frac {1}{2}}\left[\text{tr} \left(\Sigma _{1}^{-1}\Sigma _{0}\right)-k+\left(\mu _{1}-\mu _{0}\right)^{\mathsf {T}}\Sigma _{1}^{-1}\left(\mu _{1}-\mu _{0}\right)+\ln {\frac {det \Sigma _{1}}{det \Sigma _{0}}}\right] \]
在我们这里,我们令 \(p\) 和 \(q\) 的 variance 为相同的 \(\Sigma_q(t)\),因此我们可以简化 KL 散度:
\[ \begin{align*} & \quad \,\arg \min_{{\theta}} {q(x_{t-1}|x_t, x_0)}||{p_{{\theta}}(x_{t-1}|x_t)} \nonumber \\ &= \arg\min_{{\theta}}{\mathcal{N}(x_{t-1}; {\mu}_q,{\Sigma}_q(t))}||{\mathcal{N}(x_{t-1}; {\mu}_{{\theta}},{\Sigma}_q(t))}\\ &=\arg\min_{{\theta}}\frac{1}{2}\left[\log\frac{|{\Sigma}_q(t)|}{|{\Sigma}_q(t)|} - d + \text{tr}({\Sigma}_q(t)^{-1}{\Sigma}_q(t)) + ({\mu}_{{\theta}}-{\mu}_q)^T {\Sigma}_q(t)^{-1} ({\mu}_{{\theta}}-{\mu}_q)\right]\\ &=\arg \min_{{\theta}}\frac{1}{2}\left[\log1 - d + d + ({\mu}_{{\theta}}-{\mu}_q)^T {\Sigma}_q(t)^{-1} ({\mu}_{{\theta}}-{\mu}_q)\right]\\ &=\arg \min_{{\theta}}\frac{1}{2}\left[({\mu}_{{\theta}}-{\mu}_q)^T {\Sigma}_q(t)^{-1} ({\mu}_{{\theta}}-{\mu}_q)\right]\\ &=\arg \min_{{\theta}}\frac{1}{2}\left[({\mu}_{{\theta}}-{\mu}_q)^T \left(\sigma_q^2(t)\textbf{I}\right)^{-1} ({\mu}_{{\theta}}-{\mu}_q)\right]\\ &=\arg \min_{{\theta}}\frac{1}{2\sigma_q^2(t)}\left[\left\lVert{\mu}_{{\theta}}-{\mu}_q\right\rVert_2^2\right] \end{align*} \]
综上,我们的目标函数为: \[ L = \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ \sum_{t > 1} \frac{1}{2\sigma_q^2(t)}\left\lVert{\mu}_{{\theta}}(x_t, t)-{\mu}_q(x_t, x_0)\right\rVert_2^2 \right] \]
训练目标的简化
上面小节展示了我们仅仅需要学习 \(\mu_\theta\) 即可,然而众所周知神经网络对于学习无界的函数是有困难的,因此我们需要对 \(\mu_\theta\) 进行一些限制。类似于 ResNet 的设计,我们可以继续简化神经网络的训练目标。
之前我们得到了已知 \(x_0\) 下的 reverse process 的均值 \(\tilde{\mu}_t(x_t, x_0)\):
\[ \begin{align*} \tilde{\mu}_t(x_t, x_0) := \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})x_t + \sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)x_0}{\sigma_t^2} \end{align*} \]
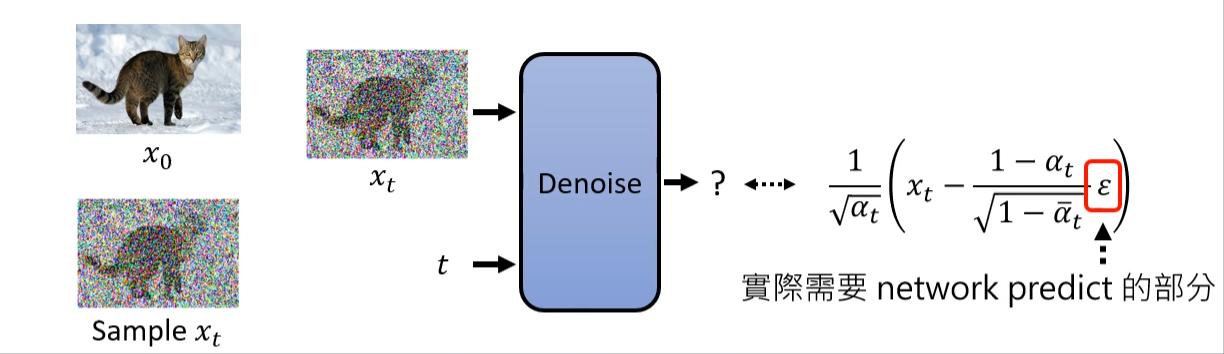
又由前向过程中已知 \(q(x_t|x_0)\): \[ x_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \varepsilon}{\sqrt{\bar{\alpha}_t}}, \quad \varepsilon \sim \mathcal{N}(0, I) \]
连立得到:
\[ \mu_q(x_t) = \frac{1}{\sqrt{\alpha_t}} x_t - \frac{1 - {\alpha}_t}{\sqrt{1 - \bar{\alpha_t}} \sqrt{\alpha_t}} \varepsilon \]
类似的,我们令神经网络的学习对象为 \(\mu_\theta(x_t, t)\),则我们可以改写训练目标为: \[ \mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha_t}} x_t - \frac{1 - {\alpha}_t}{\sqrt{1 - \bar{\alpha_t}} \sqrt{\alpha_t}} \varepsilon_\theta(x_t, t) \]
带入回目标函数 L:
\[ \begin{align*} L &= \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ \sum_{t > 1} \frac{1}{2\sigma_q^2(t)}\left\lVert{\mu}_{{\theta}}(x_t, t)-{\mu}_q(x_t, x_0)\right\rVert_2^2 \right] \\ &= \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ \sum_{t > 1} \frac{1}{2\sigma_q^2(t)}\left\lVert\frac{1}{\sqrt{\alpha_t}} x_t - \frac{1 - {\alpha}_t}{\sqrt{1 - \bar{\alpha_t}} \sqrt{\alpha_t}} \varepsilon_\theta(x_t, t) - \left(\frac{1}{\sqrt{\alpha_t}} x_t - \frac{1 - {\alpha}_t}{\sqrt{1 - \bar{\alpha_t}} \sqrt{\alpha_t}} \varepsilon\right)\right\rVert_2^2 \right] \\ &= \mathbb{E}_{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \left[ \sum_{t > 1} \frac{1}{2\sigma_q^2(t)} \frac{(1 - \alpha_t)^2}{(1 - \tilde{\alpha}_t)\alpha_t} \left\lVert \varepsilon_\theta(x_t, t) - \varepsilon \right\rVert_2^2 \right] \\ \end{align*} \]
现在,目标函数和训练对象的物理意义是训练网络预测在每个时间步添加到数据中的噪声,从而学会如何去噪。
Another Target: Score-Based Function
要推导变分扩散模型的第三种常见解释,我们要借助 Tweedie 公式 (wikipedia)。 该公式表明:给定从指数族分布中抽取的样本,其真实均值可以通过样本的最大似然估计(即经验均值)加上一个涉及估计值分数的修正项来估算。当仅观测到单个样本时,经验均值即样本自身。 该公式常用于缓解样本偏差——若观测样本均位于潜在分布的一端,则负分数值增大,从而将朴素的最大似然估计向真实均值方向修正。
你以为到此为止了吗?当然没有!
我们将引入正则系综的思想,来将我们的目标函数转化为统计物理中的 free energy.
统计物理中,正则系综研究的是与热库(heat bath)处于热平衡的粒子束守恒系统。 假设系统的能量函数为 \(E(x)\),则在温度 \(T\) 下,系统状态 \(x\) 的概率分布为:
\[ P(x) = \frac{1}{Z} \exp\left(-\frac{E(x)}{kT}\right) \]
其中 \(Z\) 是配分函数,\(k\) 是玻尔兹曼常数。
在这里,我们假设目标数据分布是处于平衡态的,即为存在这所谓的温度和能量函数的。于是,我们可以用配分函数的形式来表示数据分布:
\[ p_\theta (x) = \frac{1}{Z_\theta} e^{- f_\theta (x)} \]
但是对于复杂的真实数据分布,我们无法得到全局的归一化常数 \(Z_\theta\)。或者说,分布函数不是很光滑,我们总是会漏掉一些 spike,导致无法复原/得到整体的分布。于是,neural network 的目标就变成了: 使用神经网络 \(s_\theta(x)\) 来学习分布 \(p(x)\) 的评分函数 \(\nabla \log p(x)\):
\[ \text{min } \mathbb{E}_{x \sim P_{data}} \left[ \left\lVert s_\theta(x) - \nabla_x \log p_\theta (x) \right\rVert_2^2 \right] \]
推导: 对上式求导,得到:
\[ \begin{aligned} \nabla_x \log p_\theta (x) &= \nabla_x \log \left( \frac{1}{Z_\theta} e^{- f_\theta (x)} \right) \\ &= \nabla_x \log \frac{1}{Z_\theta} + \nabla_x \log e^{- f_\theta (x)} \\ &= - \nabla_x f_\theta (x) \approx s_\theta(x) \end{aligned} \]
得分函数表示什么含义?
对于每个数据 x,其对数似然相对于 x 的梯度本质上是在 latent space 中应向哪个方向移动以进一步提高其似然度。
直观来看,得分函数在数据 x 所处的整个空间上定义了一个向量场,指向众数方向。 通过学习真实数据分布的得分函数,我们可以从同一空间的任意点出发, 迭代地跟随得分方向直至到达众数,从而生成样本。 这种采样过程称为朗之万动力学,其数学表述为:
\[ \mathbf{x}_{i+1} \leftarrow \mathbf{x}_i + c \nabla \log p(\mathbf{x}_i) + \sqrt{2c} \mathbf{z}_i, \quad \mathbf{z}_i \sim \mathcal{N}(0, I) \]
在这种解释下,我们可以理解为什么 DDPM 需要使用噪声来采样: 这是一种变相的 MCMC 方法,引入噪声项进行采样能为生成过程增加随机性,从而避免确定性轨迹。
Training & Sampling
DDPM 原论文采用了一个简单的训练和采样流程:
# Training
for t in range(T):
sample x_t from q(x_t | x_0)
sample epsilon from N(0, I)
compute loss L_t = ||epsilon - epsilon_theta(x_t, t)||^2
update theta using L_t
# Sampling
x_T = sample from N(0, I)
for t in reversed(range(T)):
x_t = mu_theta(x_T, t) + sigma_theta(x_T, t)
x_T = x_t + sample from N(0, I)需要注意的是,在采样的过程中添加了噪音项,这使得生成的样本具有一定的随机性,从而能够生成多样化的结果。
Guidance / Prompting
之前我们只能学习一种特定的数据分布,然而,在处理含有标签的数据时,我们希望能够根据标签生成对应的样本。在这里我们简单介绍一下 DDPM 的 Guidance 技术。
之前我们的 p 推理过程是:
\[ p(x_{0:T}) = p(x_T) \prod_{t=1}^T p_\theta(x_{t-1} | x_t) \]
如果我们加上 condition 标签 \(y\),则变为:
\[ p(x_{0:T} | y) = p(x_T | y) \prod_{t=1}^T p_\theta(x_{t-1} | x_t, y) \]
y可以是图文生成中的文本编码,也可以是执行超分辨率的低分辨率图像。
该 vanilla 方法的一个注意事项是:以这种方式训练的条件扩散模型可能学会忽略或弱化给定的条件信息。因此,指导机制被提出作为一种更显式控制模型对条件信息加权程度的方法,但这会以样本多样性为代价。目前最主流的两种指导形式分别是分类器指导和无分类器指导。
Classifier Guidance
我们用基于 score function 的目标函数来解释分类器指导。在此表述下,我们的目标是在任意噪声水平下学习 \(\nabla_{x_t} \log p(x_t|y)\),代入 Bayes 公式:
\[ \begin{align*} \nabla_{x_t} \log p(x_t|y) &= \nabla_{x_t} \log \left(\frac{p(x_t)p(y|x_t)}{p(y)}\right) \\ &= \nabla \log p(x_t) + \nabla \log p(y|x_t) - \nabla \log p(y) \\ &= \nabla \log p(x_t) + \nabla \log p(y|x_t) \quad (\text{last term is constant}) \\ \end{align*} \]
可以看到,我们最后的结果是两个梯度的结合。第一部分为 score function \(\nabla \log p(x_t)\),用来进行无条件的扩散模型学习;第二部分 \(\nabla \log p(y|x_t)\) 是一个分类器的梯度,用来引导生成过程朝向目标类别 \(y\)。
为了实现精细控制以鼓励或抑制模型考虑条件信息,分类器引导技术通过超参数 \(\gamma\) 对含噪分类器的对抗梯度进行缩放。分类器引导下学习得到的评分函数可归纳为:
\[ \nabla_{x_t} \log p(x_t|y) = \nabla \log p(x_t) + \gamma \nabla \log p(y|x_t) \]
在这样的方式下,模型牺牲了一部分的样本多样性来获得更强的条件一致性。
Classifier-Free Guidance
分类器指导的一个缺点是需要训练一个额外的分类器,这在某些情况下可能并不方便。为了解决这个问题,Ho 等人提出了无分类器指导(Classifier-Free Guidance)技术。
我们将 Classifier Guidance 中的改进目标函数改写为:
\[ \nabla \log p(y|x_t) = \nabla \log p(x_t|y) - \nabla \log p(x_t) \]
添加 \(\gamma\) 得到:
\[ \begin{align*} \nabla \log p(x_t|y) &= \nabla \log p(x_t|y) + \gamma (\nabla \log p(x_t|y) - \nabla \log p(x_t)) \\ &= \gamma \nabla \log p(x_t|y) + (1 - \gamma) \nabla \log p(x_t) \\ \end{align*} \]
公式的前一项是 conditional score function,后一项是 unconditional score function。通过调整 \(\gamma\) 的值,我们可以控制模型对条件信息的关注程度。
由于学习两个独立的扩散模型成本高昂,我们可以将条件与非条件扩散模型共同学习为单一条件模型:通过将条件信息替换为固定常数值(如零值)即可查询非条件扩散模型。这本质上是对条件信息执行随机丢弃操作。无分类器引导机制的优越性在于,仅需训练单一扩散模型即可实现更精细的条件生成控制,且无需引入额外训练要素。
在CFM框架下,我们可通过公式
\[ v_{t,CFG} = v_t(\psi_t(x0), c) + \alpha (v_t(\psi_t(x_0), c) − v_t(\psi_t(x_0))) \]
调节生成样本的保真度与多样性平衡,其中α为CFG强度系数。
DDIM
DDPM 模型虽然效果极佳,但是由于其在生成噪声,因此输出具有不确定性,同时采样过程需要经历 T 步迭代,导致生成速度较慢。DDIM(Denoising Diffusion Implicit Models)是一种改进的扩散模型,旨在提高采样效率和生成质量。 简单来说,DDIM 将 markov 过程变成了非 markov 过程,通过给定确定的随机微分方程(SDE)来实现更快的采样。
简单来讲,DDIM 的采样和更新算法如下:
From \(p_\theta(x_{1:T})\), one can gengerate \(x_{t-1}\) from \(x_i\) via:
\[ x_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \left( \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \varepsilon_\theta(x_t, t)}{\sqrt{\bar{\alpha}_t}} \right) + \sqrt{1 - \bar{\alpha}_{t-1} - \sigma_t^2} \varepsilon_\theta(x_t, t) + \sigma_t z_t, \quad z_t \sim \mathcal{N}(0, I) \]
简单来说,DDIM 第一步在 \(x_t\) 就已经预测了 \(x_0\),然后通过一个确定的更新公式来得到 \(x_{t-1}\)。所以,我们的生成的内容大概率就在 \(x_0\) 附近,从而提高了生成速度。
Flow Matching
Flow Matching 是一种最近兴起的生成模型范式,在深度概率机器学习社区中迅速获得了关注。Flow Matching 结合了连续归一化流(CNFs)和扩散模型(DMs)的元素,缓解了这两种方法的关键问题。
Notations
- \(p\): the data distribution.
- \(\pi\): the prior distribution.
- \(T\): the terminal time.
Continuous Normalizing Flows (CNFs)
连续归一化流(Continuous Normalizing Flows, CNFs)是一种生成模型,旨在通过学习数据分布的连续变换来生成新样本。CNFs 的核心思想是使用微分方程来描述数据从简单分布(如高斯分布)到复杂分布(如图像分布)的演变过程。
令数据空间 \(\mathbf{x} = (x^1, \dots, x^d) \in \mathbb{R}^d\). 引入两个重要变量:
- \(p: [0, 1] \times \mathbb{R}^d \to \mathbb{R}_{>0}\), 作为时间 \(t\) 和数据 \(\mathbf{x}\) 的联合概率密度函数. \(\int p_t(x) d x = 1\)
- \(v: [0, 1] \times \mathbb{R}^d \to \mathbb{R}^d\), 作为时间 \(t\) 和数据 \(\mathbf{x}\) 的速度场(velocity field).
以上两个变量通过连续的概率流(probability flow)联系在一起:
\[ \frac{d}{dt} \phi_t(x) = v_t(\phi_t(x)), \quad \phi_0(x) = x \]
其中 \(\phi_t: \mathbb{R}^d \to \mathbb{R}^d\) 是一个随时间变化的可微函数,表示数据在时间 \(t\) 的位置。
Continuous Normalizing Flows 的目标是通过学习速度场 \(v_t(x)\) 来使得初始分布 \(p_0(x)\) 经过时间演化后变为目标分布 \(p_1(x)\)。这个过程可以通过求解以下的连续归一化流方程来实现:
\[ \frac{\partial p_t(x)}{\partial t} + \nabla \cdot (p_t(x) v_t(x)) = 0 \]
Theorem Proofs for Flow Matching
- 对于任意分布 \(q(x_1)\), 其中 \(x_1\) 是 \(p_1(x)\) 的样本,给定生成条件概率路径 \(p_t(\mathbf{x} \mid \mathbf{x}_1)\) 的向量场 \(u_t(\mathbf{x} \mid \mathbf{x}_1)\),公式8中的边缘向量场 \(u_t\) 生成公式6中的边缘概率路径 \(p_t\),即 \(u_t\) 和 \(p_t\) 满足连续性方程。
Flow Matching Theory
设 \(x_1\) 表示一个服从某未知数据分布 \(q(x_1)\) 的随机变量。 我们假设仅能获取来自 \(q(x1)\) 的数据样本,但无法获得其概率密度函数本身。 进一步地,令 \(p_t\) 为一条概率路径,其中 \(p_0 = p\) 为简单分布 (例如标准正态分布 \(p(x) = N (x|0, I)\)),且令 \(p_1\) 在分布上近似等于 \(q\)。 流匹配(Flow Matching)目标的设计旨在匹配该目标概率路径,从而使我们能够实现从 \(p_0\) 到 \(p_1\) 的流动转换。
对于目标概率路径 \(p_t(x)\) 和向量场 \(v_t(x)\), 我们定义 Flow Matching 目标为:
\[ L_{FM} (\theta) = \mathbb{E}_{t, p_t(x)} || v_t(x) - u_t(x) ||^2 \]
其中 \(\theta\) 表示 CNF 向量场 \(v_t(x)\) 的可学习参数, \(t \sim{} U[0, 1]\), \(x \sim{} p_t(x)\). 简而言之,Flow Matching 通过 \(v_t\) 对 \(u_t\) 进行回归拟合。
There are many choices of probability paths that can satisfy \(p_1(x) \approx q(x)\), and more importantly, we generally don’t have access to a closed form \(u_t\) that generates the desired \(p_t\).
构建目标概率路径的一种简单方法是通过混合更简单的概率路径: 给定特定数据样本 \(x_1\),我们以 \(p_t(x|x_1)\) 表示条件概率路径,使其在 \(t=0\) 时满足 \(p_0(x|x_1)=p(x)\),并设计 \(t=1\) 时的 \(p_1(x|x1)\) 为集中于 \(x=x_1\) 周围的分布,例如 \(p_1(x|x_1)=N(x|x_1, \sigma^2 I)\),即均值为 \(x_1\)、标准差 \(\sigma>0\) 足够小的正态分布。将条件概率路径对 \(q(x_1)\) 进行边缘化处理,即可得到边缘概率路径:
\[ p_t(x) = \int p_t(x|x_1) q(x_1) d x_1 \]
于是我们在 \(t=1\) 时近似有
\[ p_1(x) = \int p_1(x|x_1) q(x_1) d x_1 \approx q(x) \]
同样的,我们可以得到边缘向量场:
\[ u_t(x) = \int u_t(x|x_1) \frac{p_t(x|x_1)q(x_1)}{p_t(x)} d x_1 \]
遗憾的是,由于边缘概率路径和向量场的定义中存在的难解积分项,目前仍无法有效计算 \(u_t\),进而无法直接计算原始流匹配目标的无偏估计量。为此,我们提出了一个更简化的目标函数,并令人惊讶地发现该目标能够收敛到与原始目标相同的最优解。具体而言,我们定义简化的流匹配目标为:
\[ L_{CFM} (\theta) = \mathbb{E}_{t, q(x_1), p_t(x|x_1)} ||v_t(x) - u_t(x|x_1)||^2 \]
其中 \(x \sim{} p_t(x|x_1)\). 不像原始的流匹配目标,简化目标不包含难解的积分项,因此可以直接计算其无偏估计量。
D3PM
在处理图像等连续数据时,标准的 DDPM(Denoising Diffusion Probabilistic Models)模型通过逐步添加微小的高斯噪声来破坏数据。这个过程是平滑的,因为你可以在一个像素值(如 0.5)上加上一个很小的数(如 0.001)。 但在离散空间,比如文本(词汇表是有限集合)、分类数据等,状态是离散的(例如,单词 “cat” 或 “dog”)。你不能给 “cat” 的 one-hot 向量加上一点高斯噪声,因为结果向量将不再对应任何一个有效的词。因此,我们需要重新定义“加噪”和“去噪”的过程。
Categorical Transitions
在离散空间中,我们将 Forward & Reverse Process 看成是基于类别转移的马尔可夫链。
A. 前向过程 (Forward Process): 状态转移
前向过程 \(q(x_t | x_{t-1})\) 不再是添加高斯噪声,而是根据一个转移矩阵 (Transition Matrix) \(Q_t\) 将一个离散状态(如一个词)以一定概率变成另一个状态。
状态定义: 原始数据 \(x_0\) 是一个 one-hot 向量,维度为 \(K\)(例如词汇表大小)。\(x_0 \in \{0, 1\}^K\)。
单步转移: 从 \(x_{t-1}\) 到 \(x_t\) 的转移过程由一个 \(K \times K\) 的行随机矩阵(row-stochastic matrix)\(Q_t\) 定义: \[ q(x_t | x_{t-1}) = \text{Categorical}(x_t; p=x_{t-1}^T Q_t) \] 这意味着 \(x_t\) 的概率分布是通过将 \(x_{t-1}\) (one-hot 向量) 左乘转移矩阵 \(Q_t\) 得到的。矩阵 \(Q_t\) 的第 \(i\) 行第 \(j\) 列元素 \(Q_t[i, j]\) 表示状态 \(i\) 在时刻 \(t\) 转移到状态 \(j\) 的概率。
多步转移: 从原始数据 \(x_0\) 直接到 \(x_t\) 的转移概率可以通过累乘转移矩阵得到: \[ \bar{Q}_t = Q_1 Q_2 \cdots Q_t \] 因此,从 \(x_0\) 到 \(x_t\) 的分布为: \[ q(x_t | x_0) = \text{Categorical}(x_t; p=x_0^T \bar{Q}_t) \]
噪声计划 (Noise Schedule): 设计一系列的 \(Q_t\) 矩阵是这里的关键,相当于连续空间中的 \(\beta_t\)。一个常见的设计是: \[ Q_t = (1 - \beta_t)I + \beta_t \frac{1}{K} \mathbf{1}\mathbf{1}^T \] 这里,\(I\) 是单位矩阵,\(\mathbf{1}\) 是全1向量。这个公式的含义是:在第 \(t\) 步,一个 token 有 \(1-\beta_t\) 的概率保持不变,有 \(\beta_t\) 的概率均匀地变成词汇表中的任何一个词(包括它自己)。随着 \(t \to T\),\(\bar{Q}_T\) 会趋近于一个所有元素都是 \(1/K\) 的矩阵,使得最终的 \(x_T\) 的分布与 \(x_0\) 无关,变成一个均匀分布(Uniform Distribution)。这对应于连续空间中的标准正态分布。
B. 逆向过程 (Reverse Process): “去噪” -> “逆向转移”
逆向过程的目标是学习一个模型 \(p_\theta(x_{t-1} | x_t, t)\) 来逆转上述的转移过程,从一个混乱的状态 \(x_t\) 恢复出更清晰的状态 \(x_{t-1}\)。
目标: 我们需要用一个神经网络来参数化这个逆向转移概率。 \[ p_\theta(x_{t-1} | x_t, t) = \text{Categorical}(x_{t-1}; p=f_\theta(x_t, t)) \] 其中 \(f_\theta\) 是一个神经网络,输入是当前状态 \(x_t\) 和时间步 \(t\),输出是一个大小为 \(K\) 的概率分布。
真实的逆向分布: 类似于连续情况,我们可以使用贝叶斯定理推导出真实的后验分布 \(q(x_{t-1} | x_t, x_0)\): \[ q(x_{t-1} | x_t, x_0) \propto q(x_t | x_{t-1}) q(x_{t-1} | x_0) \] 这个分布是可以计算的,因为它只依赖于我们设计的前向过程矩阵 \(Q_t\) 和 \(\bar{Q}_t\)。
C. 损失函数 (Loss Function)
训练的目标是让模型学习的逆向过程 \(p_\theta(x_{t-1} | x_t)\) 尽可能地接近真实的后验 \(q(x_{t-1} | x_t, x_0)\)。这通常通过最小化它们之间的 KL 散度来实现。
最终的损失函数(一个简化的形式)可以写成: \[L = \mathbb{E}_{q(x_0)} \mathbb{E}_{t \sim [1, T]} \mathbb{E}_{q(x_t|x_0)} \left[ D_{KL}(q(x_{t-1}|x_t, x_0) || p_\theta(x_{t-1}|x_t, t)) \right]\]
在实践中,更常见的做法是让模型不直接预测 \(p_\theta(x_{t-1}|x_t)\),而是直接预测原始数据 \(\hat{x}_0\),然后用这个预测出的 \(\hat{x}_0\) 来计算 \(q(x_{t-1}|x_t, \hat{x}_0)\) 作为 \(p_\theta(x_{t-1}|x_t)\)。这使得损失函数可以简化为在所有时间步上对原始数据 \(x_0\) 的交叉熵损失 (Cross-Entropy Loss): \[L_{simple} = \mathbb{E}_{q(x_0)} \mathbb{E}_{t \sim [1, T]} \mathbb{E}_{q(x_t|x_0)} \left[ -\log p_\theta(x_0|x_t, t) \right]\] 这里 \(p_\theta(x_0|x_t, t)\) 是模型根据 \(x_t\) 预测的 \(x_0\) 的概率分布。
模型架构调整
虽然核心思想变了,但模型的主体架构通常可以沿用成熟的序列模型,比如 Transformer。
- 输入嵌入 (Input Embedding):
- Token Embedding: 离散的 token(整数索引)首先通过一个词嵌入层(Embedding Layer)映射成连续的向量,这和标准的 NLP 模型完全一样。
- 时间步嵌入 (Timestep Embedding): 时间步 \(t\) (一个整数) 也需要被嵌入到一个连续向量中,通常使用和原始 Transformer 相同的位置编码(Sinusoidal Positional Encoding)方法。
- 两者相加,作为模型的输入。
- 核心网络 (Denoising Network):
- Transformer: 对于文本等序列数据,Transformer 是最自然的选择。它通过自注意力机制(Self-Attention)可以很好地捕捉序列内部的依赖关系。
- 网络接收加噪后的词嵌入序列和时间步嵌入,任务是预测出去噪后的结果。
- 输出层 (Output Layer):
- 模型的最终输出需要经过一个 Softmax 层,生成一个在整个词汇表(大小为 \(K\))上的概率分布。这个分布就是模型对 \(x_0\)(或 \(x_{t-1}\))的预测。
总结对比
| 特性 | 连续空间 (Continuous Diffusion, e.g., DDPM) | 离散空间 (Discrete Diffusion, e.g., D3PM) |
|---|---|---|
| 数据类型 | 图像、音频 (连续值) | 文本、DNA序列、分类数据 (离散 token) |
| 前向过程 | 逐步添加高斯噪声 (Adding Gaussian Noise) | 依概率进行状态转移 (Probabilistic State Transition) |
| 数学工具 | 正态分布、均值/方差 | 类别分布、转移矩阵 (Transition Matrix) |
| 最终噪声分布 | 标准正态分布 (\(\mathcal{N}(0, I)\)) | 均匀离散分布 (Uniform Categorical Distribution) |
| 模型架构 | U-Net (图像) | Transformer (文本/序列) |
| 模型输出 | 预测噪声 \(\epsilon\) 或去噪后的图像 \(x_0\) | 预测去噪后的 token \(x_0\) 或 \(x_{t-1}\) 的概率分布 |
| 损失函数 | L1 或 L2 损失 (MSE) | 交叉熵损失 (Cross-Entropy Loss) |
这个领域的开创性工作是 D3PM (Discrete Denoising Diffusion Probabilistic Models) by Austin et al., 2021。
Masked Diffusion Model (MDM)
掩码扩散模型是一种新兴的、功能强大的生成模型,它巧妙地将扩散模型(Diffusion Models)的核心思想与自然语言处理(NLP)领域中经典的掩码语言建模(Masked Language Modeling, MLM)技术相结合。这种模型最初主要为文本等离散数据设计,但其思想也正逐步扩展到其他领域。 要彻底理解它,我们需要从它的两个组成部分说起:扩散思想和掩码机制。
核心思想:从“加噪”到“掩码”
传统的扩散模型(如DDPM)在处理图像等连续数据时,通过一个“前向过程”逐步向数据中添加高斯噪声,直至其变为纯粹的随机噪声。然后,模型学习一个“反向过程”,从噪声中逐步“去噪”,恢复出原始数据。
然而,将高斯噪声直接应用于文本这样的离散数据(由一个个独立的词元/token组成)是行不通的。词元是类别化的,无法与连续的噪声值相加。
掩码扩散模型的核心创新在于,它将“加噪”过程替换为了“掩码(Masking)”过程。
- 噪声(Noise) ↦ 掩码(Mask): 在文本数据中,“噪声”不再是数值上的扰动,而是信息的丢失。
[MASK]标记就是信息被隐藏的象征,它扮演了传统扩散模型中“噪声”的角色。
模型的工作流程:前向与反向过程
掩码扩散模型同样遵循一个逐步进行的前向过程和一个学习驱动的反向过程。
前向过程 (Forward Process / Masking Process)
这是一个固定的、无需学习的过程,其目标是逐步地、有控制地“破坏”原始文本序列。
- 起始状态 (\(t=0\)): 输入一个完整的、清晰的句子,例如:“
我 爱 人工智能”。 - 逐步掩码: 在一系列离散的时间步(从 \(t=1\) 到 \(t=T\))中,模型会按照一个预设的掩码策略(Masking Schedule)随机选择序列中的一些词元,并将它们替换为特殊的
[MASK]标记。- \(t=1\): 可能变为 “
我 爱 [MASK] 智能” - \(t=2\): 可能变为 “
[MASK] 爱 [MASK] 智能” - …
- 最终状态 (\(t=T\)): 整个序列完全被掩码,变为:“
[MASK] [MASK] [MASK] [MASK]”。
- \(t=1\): 可能变为 “
这个掩码策略是关键,它定义了在每个时间步 t,一个词元应该被掩码的概率。通常,随着时间步 t 的增加,被掩码的概率也随之增加。这确保了破坏过程是渐进的。
反向过程 (Reverse Process / Denoising Process)
这是模型需要学习的核心部分,目标与前向过程完全相反:从一个被部分或完全掩码的序列中,恢复出原始的、完整的文本。
- 起始状态 (\(t=T\)): 从一个完全被掩码的序列开始。
- 迭代式去掩码 (Iterative De-masking): 模型(通常是基于 Transformer 架构)会接收当前被部分掩码的序列以及当前的时间步
t作为输入。- 预测: 它的任务是预测所有
[MASK]位置上最有可能的原始词元。由于模型可以观察到整个序列的上下文(除了被掩码的部分),它能做出比传统自回归模型更全局的判断。 - 填充: 根据模型的预测,选择最可信的词元来填充一部分
[MASK]标记。填充策略有很多种,例如一次只填充置信度最高的几个,或者根据一个概率分布进行采样。 - 递减时间步: 将时间步从
t减到t-1,然后重复上述过程,直到t=0。
- 预测: 它的任务是预测所有
- 最终状态 (\(t=0\)): 所有的
[MASK]标记都被真实的词元替换,生成一个完整的、连贯的句子。
训练目标: 在训练时,模型会随机抽取一个时间步 t,对原始文本进行前向掩码操作得到一个被部分掩码的序列。然后,模型被要求预测出那些被掩码的原始词元是什么。其损失函数通常是被掩码词元的交叉熵损失(Cross-Entropy Loss),这与BERT等掩码语言模型的训练方式非常相似。
与相关模型的比较
vs. 传统扩散模型 (DDPM)
| 特性 | 掩码扩散模型 | 传统扩散模型 |
|---|---|---|
| 数据类型 | 离散数据 (文本) | 连续数据 (图像) |
| “加噪”方式 | 逐步掩码 (Masking) | 逐步添加高斯噪声 |
| “去噪”方式 | 预测并填充 [MASK] 标记 |
预测并减去噪声 |
| 核心机制 | 类别转换 | 数值扰动 |
vs. 掩码语言模型 (BERT)
| 特性 | 掩码扩散模型 | 掩码语言模型 (BERT) |
|---|---|---|
| 目标 | 生成模型 (Generative) | 表示模型 (Representation) |
| 训练/推理 | 迭代式、多步生成 | 一次性预测,主要用于理解和编码 |
| 输入 | 在生成时,可以从纯 [MASK] 开始 |
需要一个有意义的句子作为输入 |
| 核心区别 | 学习一个生成过程 | 学习一个上下文表示 |
vs. 自回归语言模型 (GPT)
| 特性 | 掩码扩散模型 | 自回归语言模型 (GPT) |
|---|---|---|
| 生成方式 | 并行/非自回归 | 串行/自回归 |
| 上下文依赖 | 双向上下文(一开始就能看到整个序列的长度和未掩码部分) | 单向上下文(只能看到已生成的左侧内容) |
| 生成速度 | 潜在速度更快,因为可以一次性预测多个词元 | 速度较慢,因为必须逐个词元生成 |
| 可控性 | 更容易进行文本编辑(例如替换句子中间的词) | 不易于编辑,修改前面会影响后面所有内容 |
Conclusion
作为强生成模型,Diffusion Model 知识定义了一个清晰的数学框架, 其背后的 backbone model 可以随意替换。
DDPM 是一种基于逐步去噪的生成模型,它从高斯噪声出发,利用神经网络一步步去除噪声,从而生成逼真的图像或数据。
DDPM 有两个过程:
正向扩散(Forward Process)。从真实图像 \(x_0\) 开始,逐步加噪: \[ q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t \mathbf{I}) \] 最终我们会得到纯噪声 \(x_T \sim \mathcal{N}(0, I)\)。
技巧:我们可以从任意时刻 \(t\) 直接采样出 \(x_t\): \[ x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon,\quad \epsilon \sim \mathcal{N}(0, I) \] 其中 \(\bar{\alpha}_t = \prod_{s=1}^t (1 - \beta_s)\)。
反向生成(Reverse Process)。我们希望学习一个反过程: \[ p_\theta(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) \] Ho 等人提出,只需要训练模型来预测添加进去的噪声 \(\epsilon\),然后构造均值 \(\mu_\theta\) 来还原 \(x_{t-1}\)。
训练时,最常用的损失函数是: \[ \boxed{\mathcal{L}_{\text{simple}} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t) \|^2 \right]} \]
- \(\epsilon \sim \mathcal{N}(0, I)\):真实噪声
- \(\epsilon_\theta(x_t, t)\):模型预测的噪声