graph TD
E1(("E")) --> E2(("E"))
E1 --> plus["+"]
E1 --> E3(("E"))
E2 --> a1["a"]
E3 --> E4(("E"))
E3 --> times["×"]
E3 --> E5(("E"))
E4 --> a2["a"]
E5 --> a3["a"]
Context Free Languages & Pushdown Automata
Last time we talked about Finite Automata and Regular Languages. Now we will talk about Context Free Languages and Context Free Grammars.
| Machine | Function | Syntax |
|---|---|---|
| FA | Regular Language | Regular expression |
| PDA | CFL | CFG |
FA: Finite Automata
PDA: Pushdown Automata
CFL: Context Free Language
CFG: Context Free Grammar
Context Free Grammar & Language
Definition: A Context Free Grammar (CFG) is a 4-Tuple \(G = (V, \Sigma, R, S)\) where
- \(V\) is a finite set of variables (or non-terminal symbols),
- \(\Sigma\) is a finite set of terminals (or terminal symbols),
- \(R\) is a finite set of production rules of the form \(A \to w\), where \(A \in V\) and \(w \in (V \cup \Sigma)^*\),
- \(S \in V\) is the start variable.
Derivation: A Context Free Language (CFL) is a set of strings that can be generated by a CFG \(G = (V, \Sigma, R, S)\). In other words, a string \(w \in \Sigma^*\) is in the language of \(G\) if there exists a sequence of production rules \(A_0 \to A_1 \to ... \to A_n\) such that \(A_0 = S\) and \(A_n = w\).
NoteExample: CFG for Common Languages
1. \(L = \{0^n 1^n \mid n \geq 0\}\)
\[S \to 0S1 \mid \varepsilon\]
推导示例:\(S \Rightarrow 0S1 \Rightarrow 00S11 \Rightarrow 000S111 \Rightarrow 000111\)
2. \(L = \{1^n 0^n \mid n \geq 0\}\)
\[S \to 1S0 \mid \varepsilon\]
3. \(L = \{0^n 1^n\} \cup \{1^n 0^n\}\)
\[S \to S_1 \mid S_2, \quad S_1 \to 0S_1 1 \mid \varepsilon, \quad S_2 \to 1S_2 0 \mid \varepsilon\]
Ambiguity
Why: for a string \(w \in \Sigma^*\), there are multiple distinct derivation trees for \(w\).
derivation tree: a tree where each node is a production rule and each edge is a terminal symbol.
To handle ambiguity, we define the leftmost derivation:
A derivation of a string \(w\) in a grammar \(G\) is a leftmost derivation, if at every step the leftmost remaining variable is the one replaced.
Then we can define Ambiguous CFG:
A string w is derived ambiguously by a context free grammar \(G\) if it has two or more different leftmost derivations. And, grammar \(G\) is ambiguous if there exists a string \(w \in \Sigma^*\) that is derived ambiguously by \(G\).
- There is no algorithm for resolving ambiguity (in the sense of automatically deriving an unambiguous grammar from a given grammar).
- There is not even an algorithm for finding out whether a given CFG is ambiguous.
However, there are standard techniques for writing an unambiguous grammar that help in most cases.
NoteExample: Ambiguity in Arithmetic Expressions
考虑文法 \(G\):
\[\langle \text{EXPR} \rangle \to \langle \text{EXPR} \rangle + \langle \text{EXPR} \rangle \mid \langle \text{EXPR} \rangle \times \langle \text{EXPR} \rangle \mid (\langle \text{EXPR} \rangle) \mid a\]
字符串 \(a + a \times a\) 有两种不同的最左推导:
推导 1(先展开左 +):
推导 2(先展开左 ×):
graph TD
E1(("E")) --> E2(("E"))
E1 --> times["×"]
E1 --> E3(("E"))
E2 --> E4(("E"))
E2 --> plus["+"]
E2 --> E5(("E"))
E4 --> a1["a"]
E5 --> a2["a"]
E3 --> a3["a"]
两棵不同的推导树给出不同的计算结果:推导 1 对应 \(a + (a \times a)\),推导 2 对应 \((a + a) \times a\)。这就是为什么编程语言需要消歧义文法(通过设定运算符优先级和结合性)。
NoteInherently Ambiguous Languages
有些语言天生歧义:无论你怎么写 CFG,生成该语言的文法都是歧义的。
例:\(L = \{a^i b^j c^k \mid i = j \text{ or } j = k\}\) 是一个固有歧义语言。
直觉:当 \(i = j = k\) 时,字符串 \(a^n b^n c^n\) 既满足 \(i = j\) 又满足 \(j = k\),任何 CFG 都无法避免为这类字符串产生两种本质不同的推导。
Chomsky Normal Form
Definition: A CFG is in Chomsky Normal Form (CNF) if it satisfies the following conditions:
- \(A \to BC\)
- \(A \to a\)
- allow \(S \to \varepsilon\) (prevent S in the right side of production rules)
where \(a\) is any terminal and \(B, C \in V\), $$
Theorem: Every CFL is generated by a CFG in Chomsky Normal Form.
proof: create an algo to transform a CFG into a CFG in Chomsky Normal Form.
Create a new \(S_0\) to prevent \(S\) from being a variable.
Remove every \(A \to \varepsilon\), where \(A \neq S_0\).
For each occurrence of \(A\) on the RHS of a rule, we add a new rule with that occurrence deleted.
- For \(R \to uAv\) we add \(R \to uv\),
- Do the above operation for each occurrence of \(A\) on the RHS of a rule. e.g. \(R \to uAvAw\), we add \(R \to uvAw | uAvw | uvw\),
- For \(R \to A\), we add \(R \to \varepsilon\) unless we had previously removed \(R \to \varepsilon\).
Remove every \(A \to B\):
Whenever \(B \to u\) is a rule, where \(u\) is string of variables and terminals, we add the rule \(A \to u\) unless this was removed in step 2.
Replace \(A \to u_1u_2u_3...u_k, (k \geq 3)\) with \(A \to u_1B_1, B_1 \to u_2B_2, B_2 \to u_3...B_{k-1} \to u_k\). And we define \(U_i\) and \(U_i \to u_i\) to replace \(u_i\) in \(A \to u_1u_2u_3...u_k\).
Q.E.D.
Theorem: if \(G\) is a CFG in Chomsky Normal Form, then any \(w \in L(G) \land w \neq \varepsilon\) can be derived from the start state in exactly \(2 |w| - 1\) steps.
Examples: w = htefg, steps = 9
graph TD
A((A)); B((B)); C((C)); D((D)); E((E));
F((F)); G((G)); H((H)); I((I));
h[h]; t[t]; e[e]; f[f]; g[g];
A --> B; A --> C;
B --> D; B --> E;
C --> F; C --> G;
D --> H; D --> I;
H --> h;
I --> t;
E --> e;
F --> f;
G --> g;
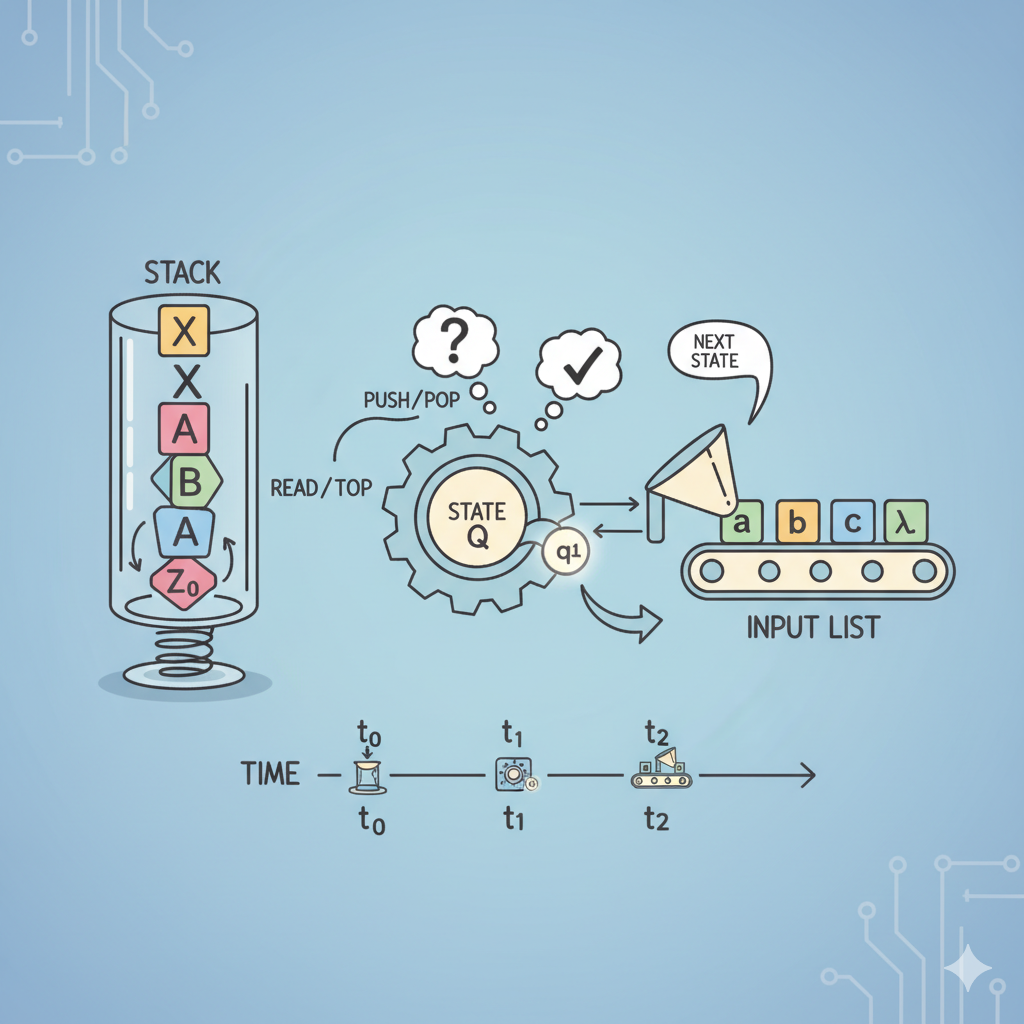
Pushdown Automata
Definition: A Pushdown Automaton (PDA) is a 6-tuple \((Q, \Sigma, \Gamma, \delta, q_0, F)\) where
- \(Q\) is a finite set called the states.
- \(\Sigma\) is a finite set called the input alphabet.
- \(\Gamma\) is a finite set called the stack alphabet.
- \(\delta: Q \times \Sigma \cup \{\varepsilon\} \times \Gamma_\varepsilon \to P(Q \times \Gamma_\varepsilon)\) is the transition function.
- \(q_0 \in Q\) is the start state.
- \(F \subseteq Q\) is the set of accept states.
When the PDA reads a symbol from the input string, it can:
- Push: Push the symbol onto the stack. This means that the symbol will be stored on the stack and will be processed later.
- Pop: Pop the topmost symbol off the stack. This means that the symbol will be removed from the stack and will not be processed again.
- No-op: Do not modify the stack. This means that the PDA will not store or remove any symbols from the stack.
The stack is used to keep track of the current position within the input string, as well as any context that is needed to process the string. For example, if the PDA needs to remember a symbol that was read earlier in the string, it can store that symbol on the stack and retrieve it later when it is needed.
Formal definition of computation
Let \(M = (Q, \Sigma, \Gamma, \delta, q_0, F)\) be a PDA and let \(w = w_1 w_2 ... w_m\) be a string with \(w_i \in \Sigma\) for \(\forall i \in [m]\).
Define: M accepts w if there exists a sequence of states \(r_0, r_1, ..., r_m \in Q\) and sequences of strings \(s_0, s_1, ..., s_m \in \Gamma^\star\) such that:
- \(r_0 = q_0\) and \(s_0 = \varepsilon\) (start in initial state with empty stack).
- For each \(i\) (\(0 \leq i < m\)), we have \((r_{i+1}, b) \in \delta(r_i, w_{i+1}, a)\), where \(s_i = at\) and \(s_{i+1} = bt\) for some \(a, b \in \Gamma_\varepsilon\) and \(t \in \Gamma^\star\) (each step follows a valid transition).
- \(r_m \in F\) (end in an accept state).
The end state must have a empty stack!
NoteExample: PDA for \(\{0^n 1^n \mid n \geq 0\}\)
构造 PDA \(M = (\{q_1, q_2, q_3, q_4\}, \{0, 1\}, \{0, \$\}, \delta, q_1, \{q_1, q_4\})\):
stateDiagram-v2
direction LR
[*] --> q1
q1 --> q2: ε, ε → $
q2 --> q2: 0, ε → 0
q2 --> q3: 1, 0 → ε
q3 --> q3: 1, 0 → ε
q3 --> q4: ε, $ → ε
q4 --> [*]
工作原理:
- \(q_1 \to q_2\):压入栈底标记 \(\$\)
- \(q_2\):读 0 时将 0 压栈
- \(q_2 \to q_3\):读第一个 1 时弹出一个 0
- \(q_3\):继续读 1 并弹出 0
- \(q_3 \to q_4\):当遇到栈底标记 \(\$\) 时,0 全部匹配完毕,接受
若输入为 \(0011\):栈变化为 \(\varepsilon \to \$ \to \$0 \to \$00 \to \$0 \to \$ \to \varepsilon\)。✓
Theorem: A language is context free if and only if it is accepted by some PDA.
NoteProof
Proof: Let \(G = (V, \Sigma, R, S)\) be a CFG.
Only If (\(\Rightarrow\)): Suppose \(L\) is a CFL generated by CFG \(G\). We construct a PDA \(M = (Q, \Sigma, \Gamma, \delta, q_0, F)\) that accepts \(L\).
- \(Q = \{q_{start}, q_{loop}, q_{accept}\}\)
- \(\Gamma = V \cup \Sigma\) (stack alphabet includes variables and terminals)
- \(q_0 = q_{start}\), \(F = \{q_{accept}\}\)
- Transition function \(\delta\):
- \((q_{loop}, S) \in \delta(q_{start}, \varepsilon, \varepsilon)\) - push start symbol
- For each rule \(A \to w\) in \(R\): \((q_{loop}, w) \in \delta(q_{loop}, \varepsilon, A)\) - replace variable with production
- For each \(a \in \Sigma\): \((q_{loop}, \varepsilon) \in \delta(q_{loop}, a, a)\) - match terminal
- \((q_{accept}, \varepsilon) \in \delta(q_{loop}, \varepsilon, \varepsilon)\) - accept when stack is empty
If (\(\Leftarrow\)): Suppose PDA \(M = (Q, \Sigma, \Gamma, \delta, q_0, F)\) accepts \(L\). We construct a CFG \(G = (V, \Sigma, R, S)\) that generates \(L\).
- Variables: \(V = \{A_{pq} \mid p, q \in Q\}\) where \(A_{pq}\) generates strings that take PDA from state \(p\) with empty stack to state \(q\) with empty stack
- Start symbol: \(S = A_{q_0, q_{accept}}\) for some \(q_{accept} \in F\)
- Production rules:
- For each \(p, q, r, s \in Q\): \(A_{pq} \to A_{pr}A_{rq}\)
- For each transition that pushes: if \((r, t) \in \delta(p, a, \varepsilon)\) and \((q, \varepsilon) \in \delta(s, b, t)\), add \(A_{pq} \to aA_{rs}b\)
- For each transition that doesn’t push: if \((q, \varepsilon) \in \delta(p, a, \varepsilon)\), add \(A_{pq} \to a\)
- For all \(p \in Q\): \(A_{pp} \to \varepsilon\)
Q.E.D.
Claim 1: If \(A_{pq}\) generates \(x\), then \(x\) can bring PDA \(P\) from state \(p\) with empty stack to state \(q\) with empty stack.
NoteProof of Claim 1
Proof by induction on the number of steps in the derivation of \(x\) from \(A_{pq}\).
Base case: If \(A_{pq} \Rightarrow x\) in one step, then either: - \(A_{pq} \to \varepsilon\) (so \(p = q\) and \(x = \varepsilon\)), or - \(A_{pq} \to a\) where \((q, \varepsilon) \in \delta(p, a, \varepsilon)\)
In both cases, \(x\) brings PDA from \(p\) to \(q\) with empty stack.
Inductive step: Assume the claim holds for all derivations of length \(\leq k\). Consider a derivation of length \(k+1\).
The first step must be one of: 1. \(A_{pq} \Rightarrow A_{pr}A_{rq} \Rightarrow^* xy\) where \(A_{pr} \Rightarrow^* x\) and \(A_{rq} \Rightarrow^* y\)
By IH, \(x\) brings PDA from \(p\) to \(r\) with empty stack, and \(y\) brings PDA from \(r\) to \(q\) with empty stack. Thus \(xy\) brings PDA from \(p\) to \(q\) with empty stack.
\(A_{pq} \Rightarrow aA_{rs}b \Rightarrow^* ayb\) where \(A_{rs} \Rightarrow^* y\)
By construction, \((r, t) \in \delta(p, a, \varepsilon)\) and \((q, \varepsilon) \in \delta(s, b, t)\).
By IH, \(y\) brings PDA from \(r\) to \(s\) with empty stack.
Therefore: reading \(a\) pushes \(t\) and goes from \(p\) to \(r\), then \(y\) goes from \(r\) to \(s\) with empty stack, then reading \(b\) pops \(t\) and goes from \(s\) to \(q\).
Thus \(ayb\) brings PDA from \(p\) to \(q\) with empty stack.
Q.E.D.
Claim 2: If \(x\) can bring PDA \(P\) from state \(p\) with empty stack to state \(q\) with empty stack, then \(A_{pq}\) generates \(x\).
NoteProof of Claim 2
Proof by induction on the number of steps taken by PDA \(P\) to go from \(p\) to \(q\) on input \(x\).
Base case: If \(P\) goes from \(p\) to \(q\) in 0 steps, then \(p = q\) and \(x = \varepsilon\). By construction, we have the rule \(A_{pp} \to \varepsilon\), so \(A_{pq}\) generates \(x\).
Inductive step: Assume the claim holds for all computations of length \(\leq k\). Consider a computation of length \(k+1\) that takes \(P\) from \(p\) to \(q\) on input \(x\).
There are two cases:
The stack is empty at some intermediate step: Suppose the stack becomes empty at state \(r\) after reading prefix \(y\) of \(x\), and then goes from \(r\) to \(q\) on the remaining suffix \(z\) (so \(x = yz\)).
By IH, \(A_{pr}\) generates \(y\) and \(A_{rq}\) generates \(z\).
By construction, we have the rule \(A_{pq} \to A_{pr}A_{rq}\).
Therefore \(A_{pq} \Rightarrow A_{pr}A_{rq} \Rightarrow^* yz = x\).
The stack is never empty until the end: In this case, the first step must push some symbol \(t\) onto the stack, and the last step must pop \(t\) from the stack.
Let \(x = ayb\) where:
- Reading \(a\) transitions from \(p\) to some state \(r\) and pushes \(t\): \((r, t) \in \delta(p, a, \varepsilon)\)
- Reading \(y\) takes PDA from \(r\) to some state \(s\) with \(t\) still on bottom of stack
- Reading \(b\) pops \(t\) and transitions from \(s\) to \(q\): \((q, \varepsilon) \in \delta(s, b, t)\)
By IH, \(A_{rs}\) generates \(y\).
By construction, we have the rule \(A_{pq} \to aA_{rs}b\).
Therefore \(A_{pq} \Rightarrow aA_{rs}b \Rightarrow^* ayb = x\).
Q.E.D.
Closure Properties
Theorem: CFL is closed under union, concatenation, and Kleene star. (Assume CFL is described by \((V, \Sigma, R, S)\))
NoteProof of Union
Let \(N_1 = (V_1, \Sigma_1, R_1, S_1)\) recognize \(A_1\) and \(N_2 = (V_2, \Sigma_2, R_2, S_2)\) recognize \(A_2\).
W.l.o.g. \(V_1 \cap V_2 = \emptyset\).
Union: \(S\) is a new symbol. Let \(N = (V_1 \cup V_2 \cup \{S\}, \Sigma_1 \cup \Sigma_2, R, S)\), where \(R = R_1 \cup R_2 \cup \{S \to S_1, S \to S_2\}\).
NoteProof of Concatenation
Let \(N_1 = (V_1, \Sigma_1, R_1, S_1)\) recognize \(A_1\) and \(N_2 = (V_2, \Sigma_2, R_2, S_2)\) recognize \(A_2\).
W.l.o.g. \(V_1 \cap V_2 = \emptyset\).
Concatenation: \(S\) is a new symbol. Let \(N = (V_1 \cup V_2 \cup \{S\}, \Sigma_1 \cup \Sigma_2, R, S)\), where \(R = R_1 \cup R_2 \cup \{S \to S_1S_2\}\).
NoteProof of Kleene Star
Let \(N_1 = (V_1, \Sigma_1, R_1, S_1)\) recognize \(A_1\).
Kleene Star: \(S\) is a new symbol. Let \(N = (V_1 \cup \{S\}, \Sigma_1, R, S)\), where \(R = R_1 \cup \{S \to \varepsilon, S \to SS_1\}\).
Theorem: The intersection of a context-fee language with a regular language is a context-free language.
NoteProof
Proof: Let PDA \(M_1 = (Q_1, \Sigma, \Gamma_1, \delta_1, s_1, F_1)\) recognize CFL \(A_1\) and DFA \(M_2 = (Q_2, \Sigma, \delta_2, s_2, F_2)\) recognize regular language \(A_2\).
Construct PDA \(M = (Q, \Sigma, \Gamma_1, \Delta, s, F)\) where:
- \(Q = Q_1 \times Q_2\)
- \(s = (s_1, s_2)\)
- \(F = F_1 \times F_2\)
- \(\Delta\) is defined as follows:
- For each PDA rule \((p_1, r) \in \delta_1(q_1, a, \beta)\) and each \(q_2 \in Q_2\), add the rule: \[((p_1, \delta_2(q_2, a)), r) \in \Delta((q_1, q_2), a, \beta)\]
- For each PDA rule \((p_1, r) \in \delta_1(q_1, \varepsilon, \beta)\) and each \(q_2 \in Q_2\), add the rule: \[((p_1, q_2), r) \in \Delta((q_1, q_2), \varepsilon, \beta)\]
The PDA \(M\) simulates \(M_1\) and \(M_2\) in parallel, accepting if both accept.
Q.E.D.
Pumping Lemma
Pumping Lemma for Context-Free Languages
If \(A\) is a context-free language, then there exists a number \(p\) (the pumping length) where, if \(s\) is any string in \(A\) of length at least \(p\), then \(s\) may be divided as \(s = uvxyz\) satisfying the following conditions:
- For each \(i \geq 0\), \(uv^ixy^iz \in A\),
- \(|vy| > 0\),
- \(|vxy| \leq p\).
NoteProof
证明: 设 \(A\) 是由 Chomsky 范式的 CFG \(G = (V, \Sigma, R, S)\) 生成的 CFL。
设 \(b = |V|\) 为 \(G\) 中变量的个数。
设泵长度 \(p = 2^b\)。
考虑任意字符串 \(s \in A\) 且 \(|s| \geq p\)。根据 CNF 推导的定理,\(s\) 有一个至少包含 \(2|s| - 1 \geq 2p - 1 = 2^{b+1} - 1\) 个节点的推导树。(最小树)
由于每个内部节点恰好有 2 个子节点(根据 CNF),该树的高度至少为 \(b + 1\)。
考虑从根到叶子的最长路径。该路径长度 \(> b\),因此它包含至少 \(b + 1\) 个变量。
根据鸽巢原理,某个变量 \(R\) 必定在此路径上重复出现。
设 \(R\) 的两次出现在高度 \(h_1\) 和 \(h_2\) 处,其中 \(h_1 < h_2 \leq b + 1\)。
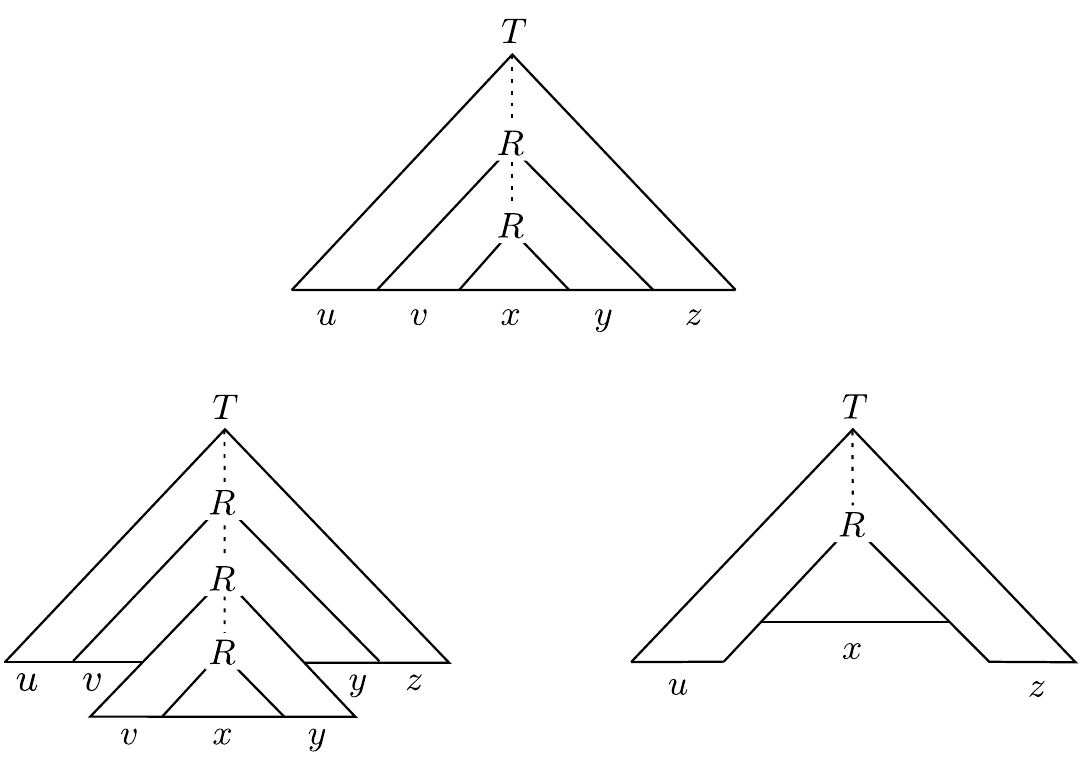
我们可以将 \(s\) 写成 \(s = uvxyz\) 的形式,其中:
- 较高位置的 \(R\) 生成 \(vxy\)
- 较低位置的 \(R\) 生成 \(x\)
- 这些子树之外的部分生成 \(u\) 和 \(z\)
那么: 1. 对所有 \(i \geq 0\),\(uv^ixy^iz \in A\)(通过将较高位置的 \(R\) 为根的子树替换为其自身的副本) 2. \(|vy| > 0\),因为以 \(R\) 为根的两个子树必定不同(否则我们可以使用更短的推导) 3. \(|vxy| \leq p\),因为较高位置的 \(R\) 在底部 \(b + 1\) 层内,最多可以生成 \(2^{b+1} - 1 < 2^{b+1} = 2p\) 个终结符
Q.E.D.
NoteExamples
\(\{a^n b^n c^n | n \geq 0\}\) is not a CFL:
假设 \(L = \{a^n b^n c^n | n \geq 0\}\) 是 CFL。设 \(p\) 为泵长度。
考虑字符串 \(s = a^p b^p c^p \in L\),其中 \(|s| = 3p \geq p\)。
根据泵引理,存在分解 \(s = uvxyz\) 满足:
- \(|vy| > 0\)
- \(|vxy| \leq p\)
- 对所有 \(i \geq 0\),\(uv^ixy^iz \in L\)
由于 \(|vxy| \leq p\),子串 \(vxy\) 最多包含两种字符(不能同时跨越 \(a\)、\(b\) 和 \(c\) 三个区域)。
因此 \(vy\) 最多包含两种字符。当我们泵 \(i = 2\) 时,\(uv^2xy^2z\) 会增加某些字符的数量,但不会增加所有三种字符的数量。
这意味着 \(uv^2xy^2z\) 中 \(a\)、\(b\)、\(c\) 的数量不相等,因此 \(uv^2xy^2z \notin L\)。
矛盾!所以 \(L\) 不是 CFL。
\(\{ww \mid w \in \{0, 1\}^*\}\) is not a CFL:
假设 \(L = \{ww \mid w \in \{0, 1\}^*\}\) 是 CFL。设 \(p\) 为泵长度。
考虑字符串 \(s = 0^p 1^p 0^p 1^p \in L\),\(|s| = 4p \geq p\)。
根据泵引理,\(s = uvxyz\) 满足 \(|vxy| \leq p\)。
由于 \(|vxy| \leq p\),\(vxy\) 不能同时横跨所有四个块。分情况讨论:
- 若 \(vxy\) 落在前两个块 \(0^p 1^p\) 内:泵后 \(uv^2xy^2z\) 的前半部分长度改变,后半部分 \(0^p 1^p\) 不变,不再是 \(ww\) 的形式。
- 若 \(vxy\) 跨越中间的 \(1^p 0^p\) 分界:泵后破坏了 \(1^p\) 和 \(0^p\) 的交界结构,结果也不是 \(ww\) 形式。
- 若 \(vxy\) 落在后两个块内:类似地,前半部分不变,后半部分改变。
所有情况下 \(uv^2xy^2z \notin L\),矛盾!
CFL Non-Closure Properties
Theorem: CFL 对交集(intersection)和补集(complementation)不封闭。
NoteProof
对交集不封闭:
设 \(L_1 = \{a^n b^n c^m \mid n, m \geq 0\}\) 和 \(L_2 = \{a^m b^n c^n \mid m, n \geq 0\}\)。
\(L_1\) 是 CFL(文法:\(S \to AB, A \to aAb \mid \varepsilon, B \to cB \mid \varepsilon\))。
\(L_2\) 是 CFL(文法:\(S \to AB, A \to aA \mid \varepsilon, B \to bBc \mid \varepsilon\))。
但 \(L_1 \cap L_2 = \{a^n b^n c^n \mid n \geq 0\}\),由泵引理可知这不是 CFL。
因此 CFL 对交集不封闭。
对补集不封闭:
由 De Morgan 律:\(L_1 \cap L_2 = \overline{\overline{L_1} \cup \overline{L_2}}\)。
若 CFL 对补集封闭,由于 CFL 对并集封闭,则 CFL 对交集也封闭——矛盾。
Q.E.D.
Decision Problems
- Acceptance: does a given string belong to a given language?
- Emptiness: is a given language empty?
- Equality: are given two languages equal?
The Acceptance and Emptiness problem for CFG are decidable, the Equality problem is not decidable.
NoteWhy
可判定 (Decidable)的含义:存在一个算法(图灵机),对于该问题的任何输入,该算法总能在有限时间内停机,并给出“是”或“否”的正确答案。
1. 接受问题 (Acceptance Problem, \(A_{CFG}\)) - 可判定
问题定义: 给定一个 CFG \(G\) 和一个字符串 \(w\),问 \(w\) 是否可以由 \(G\) 生成(即,\(w \in L(G)\))?
为什么可判定?
核心思想是:对于一个给定长度的字符串 \(w\),如果它能被文法 \(G\) 生成,那么生成它的推导步骤数是有限的。我们可以系统性地检查所有可能的推导,看是否能生成 \(w\)。
一个可靠的判定算法如下:
- 预处理: 将文法 \(G\) 转换为乔姆斯基范式 (Chomsky Normal Form, CNF)。任何不生成空串的 CFG 都可以被转换成 CNF。在 CNF 中,所有产生式规则都形如 \(A \to BC\) 或 \(A \to a\)(其中 A, B, C 是变量,a 是终结符)。
- 计算推导步数: 如果字符串 \(w\) 的长度为 \(n\) (\(n>0\)),那么在 CNF 中,任何生成 \(w\) 的推导都恰好需要 \(2n-1\) 步。这是一个非常关键的性质,因为它为我们的搜索提供了一个明确的上限。
- 有限搜索: 我们只需要检查所有长度为 \(2n-1\) 的推导序列。这是一个庞大但有限的数量。我们可以通过动态规划(例如 CYK 算法)或穷举搜索来完成这个过程。
- 结论: 因为算法总能在有限步骤内检查完所有可能的、长度固定的推导,所以它一定会停机并给出“是”(如果找到了生成 \(w\) 的推导)或“否”(如果检查完所有可能都找不到)的答案。
因此,\(A_{CFG}\) 是可判定的。
2. 空性问题 (Emptiness Problem, \(E_{CFG}\)) - 可判定
问题定义: 给定一个 CFG \(G\),问它生成的语言是否为空(即,\(L(G) = \emptyset\))?
为什么可判定?
核心思想是:一个文法能生成字符串,当且仅当它的开始符号 \(S\) 能够推导出一个由终结符组成的字符串。我们可以反向工作,找出所有能够生成终结符串的变量。
判定算法如下(标记算法):
- 初始标记: 首先,标记文法 \(G\) 中所有的终结符。
- 迭代标记: 重复以下步骤,直到没有新的变量可以被标记:
- 遍历所有产生式规则 \(A \to \alpha\)。
- 如果规则右侧 \(\alpha\) 中的所有符号(无论是终结符还是变量)都已经被标记,那么就标记规则左侧的变量 \(A\)。
- 检查开始符号: 在算法结束后(即没有新变量可标记时),检查文法的开始符号 \(S\) 是否被标记。
- 如果 \(S\) 被标记了,说明 \(S\) 最终可以推导出一个完全由终结符组成的字符串,因此 \(L(G) \neq \emptyset\)。
- 如果 \(S\) 没有被标记,说明从 \(S\) 出发无论如何也无法推导出纯终结符串,因此 \(L(G) = \emptyset\)。
因为文法中的变量数量是有限的,这个标记过程必然会在有限步内结束。所以该算法总能停机并给出明确的“是”或“否”的答案。
因此,\(E_{CFG}\) 是可判定的。
3. 等价性问题 (Equality Problem, \(EQ_{CFG}\)) - 不可判定
问题定义: 给定两个 CFG \(G_1\) 和 \(G_2\),问它们生成的语言是否相等(即,\(L(G_1) = L(G_2)\))?
为什么不可判定?
这个问题的难度是根本性的。与正则语言不同,上下文无关语言的集合在交集和补集运算下不是封闭的。这意味着我们不能像比较两个 DFA 那样,通过 \(L(G_1) \cap \overline{L(G_2)} = \emptyset\) 的方式来判断等价性。
证明其不可判定需要用到归约 (Reduction) 的思想:如果我们能解决 \(EQ_{CFG}\),那么我们就能解决某个已知的不可判定问题。这是一个矛盾,因此 \(EQ_{CFG}\) 必然是不可判定的。
通常的证明思路如下:
引入一个已知的不可判定问题: \(ALL_{CFG}\) 问题。这个问题问的是:给定一个 CFG \(G\),它的语言是否是所有可能的字符串(即,\(L(G) = \Sigma^*\))?可以证明,\(ALL_{CFG}\) 是不可判定的(其证明本身通常从“波斯特对应问题” PCP 归约而来,相当复杂)。
进行归约: 假设我们有一个可以解决 \(EQ_{CFG}\) 的算法,我们称之为
Decider_EQ。现在我们来用它解决 \(ALL_{CFG}\) 问题。- 对于任何给定的 CFG \(G\) 和字母表 \(\Sigma\),我们可以轻易地构造出另一个文法 \(G_{all}\),使得 \(L(G_{all}) = \Sigma^*\)。(例如,对于 \(\Sigma=\{0, 1\}\),规则可以是 \(S \to 0S | 1S | \epsilon\))。
- 现在,为了判断 \(L(G)\) 是否等于 \(\Sigma^*\),我们只需要调用
Decider_EQ,问它 \(L(G)\) 是否等于 \(L(G_{all})\)。 Decider_EQ(G, G_{all})的“是/否”答案,就直接对应了 \(ALL_{CFG}\) 问题的“是/否”答案。
得出结论: 这意味着,如果我们能判定两个 CFG 是否等价,我们就能判定一个 CFG 是否生成所有字符串。但我们已经知道后者 (\(ALL_{CFG}\)) 是不可判定的,所以前者 (\(EQ_{CFG}\)) 必然也是不可判定的。
总结
| 问题 | 名称 | 可判定性 | 核心原因 |
|---|---|---|---|
| 接受问题 | \(A_{CFG}\) | 可判定 | 字符串长度 n 决定了推导步数的有限上界,可以进行有限搜索。 |
| 空性问题 | \(E_{CFG}\) | 可判定 | 变量数量是有限的,可以通过有限次迭代找出所有能生成终结符串的变量。 |
| 等价性问题 | \(EQ_{CFG}\) | 不可判定 | 问题的内在复杂性太高(CFL 对交、补运算不封闭)。可以通过归约证明,解决它等价于解决一个已知的不可判定问题(\(ALL_{CFG}\))。 |
Deterministic PDA (DPDA)
A DPDA is a 6-tuple \((Q, \Sigma, \Gamma, \delta, q_0, F)\) where:
- \(Q\) is a finite set of states
- \(\Sigma\) is a finite input alphabet
- \(\Gamma\) is a finite stack alphabet
- \(\delta: Q \times (\Sigma \cup \{\varepsilon\}) \times \Gamma^* \to \mathcal{P}(Q \times \Gamma^*) \cup \{\emptyset\}\) is the transition function
- \(q_0 \in Q\) is the initial state
- \(F \subseteq Q\) is the set of accept states
For every \(q \in Q\), \(a \in \Sigma\) and \(x \in \Gamma\), exactly one of the values \(\delta(q, a, x)\), \(\delta(q, a, \varepsilon)\), \(\delta(q, \varepsilon, x)\) and \(\delta(q, \varepsilon, \varepsilon)\) is not \(\emptyset\).
DPDA 相对于 PDA 的区别在于,DPDA 在每个状态下,对于给定的输入符号和栈顶符号,只有唯一确定的转移。而 PDA 可以有多个可能的转移(非确定性)。重要的是,DPDA 识别的语言类严格小于 CFL,即存在某些 CFL 无法被任何 DPDA 识别。
DPDA Acceptance and Rejection
DPDA 可能以三种方式拒绝输入:
- 读完所有输入后不在接受状态
- 试图弹出空栈(stuck)
- 陷入无限 \(\varepsilon\)-转移循环(loop)
注意:后两种情况在 NFA/PDA 中不会导致问题(不确定性可以”选择”其他分支),但在 DPDA 中会导致计算中止或不停机。
Every DPDA Has Equivalent DPDA That Reads Entire Input
Lemma: 对任意 DPDA \(M\),存在等价的 DPDA \(M'\),使得 \(M'\) 总能读完整个输入(不会提前 stuck 或 loop)。
NoteProof Sketch
需要处理两种异常:
Hanging(挂起):\(M\) 试图弹出空栈。解决:在栈底加一个永久标记 \(\$\),当看到 \(\$\) 时,不弹栈而是做特殊处理。
Looping(循环):\(M\) 在不读输入的情况下做无限 \(\varepsilon\)-转移。解决:设 \(M\) 有 \(|Q|\) 个状态和 \(|\Gamma|\) 个栈符号。如果 \(M\) 连续做了超过 \(|Q| \cdot |\Gamma|\) 步 \(\varepsilon\)-转移而未读输入,则必然进入了循环(鸽巢原理:状态 + 栈顶的组合数有限)。此时强制进入一个拒绝并读完输入的状态。
构造出的 \(M'\) 对每个输入都会读完并停机。
Q.E.D.
DCFL is Closed Under Complementation
Theorem: DCFL 对补集封闭。即若 \(L\) 是 DCFL,则 \(\overline{L}\) 也是 DCFL。
注意:不能简单交换接受和拒绝状态!因为 DPDA 可能在读完输入之前就接受(通过 \(\varepsilon\)-转移进入接受状态,然后又离开)。
NoteProof
利用上面的引理,先将 DPDA 转换为总能读完输入的 DPDA \(M'\)。
定义读取状态(reading state):\(M'\) 在读取每个输入符号时经过的状态。读取状态之间,\(M'\) 可能做若干 \(\varepsilon\)-转移。
\(M'\) 在输入 \(w\) 上的接受取决于它在读取 \(w\) 的过程中是否经过了接受状态。更精确地说:
将 \(M'\) 的状态分为三类:
- 接受态且后续不离开接受状态集的读取状态
- 其他读取状态
对 \(M'\) 做变换:
- 先确保 \(M'\) 总能读完输入(已有引理保证)
- 跟踪”自上次读取输入以来是否经过接受状态”
- 反转最终判定:若 \(M'\) 从未在读取后处于接受状态,则 \(M''\) 接受;否则拒绝
由于反转后得到的 \(M''\) 仍然是 DPDA,\(\overline{L}\) 是 DCFL。
Q.E.D.
Corollary: 若 \(L\) 是 CFL 但 \(\overline{L}\) 不是 CFL,则 \(L\) 不是 DCFL。
NoteExample
\(L = \{a^i b^j c^k \mid i \neq j \text{ or } j \neq k\}\) 是 CFL(可以构造 PDA,非确定性地猜测是 \(i \neq j\) 还是 \(j \neq k\))。
但 \(\overline{L} = \{a^n b^n c^n \mid n \geq 0\} \cup \{w \mid w \notin a^* b^* c^*\}\) 包含 \(\{a^n b^n c^n\}\)(模去格式检查部分),而我们已知后者不是 CFL。
因此 \(L\) 不是 DCFL。
Endmarked Languages
Definition: 对语言 \(A\),定义右端标记语言 \(A\dashv = \{w\dashv \mid w \in A\}\),其中 \(\dashv\) 是一个不属于原字母表的新符号(endmarker)。
Theorem: \(A\) 是 DCFL \(\iff\) \(A\dashv\) 是 DCFL。
端标记的作用:DPDA 在看到 \(\dashv\) 时知道输入已经结束,可以据此做出最终判断。这消除了 DPDA “不知道输入何时结束”的问题。
Reductions(Bottom-Up Parsing)
定义:给定 CFG \(G = (V, \Sigma, R, S)\),对字符串 \(\alpha\),若存在规则 \(A \to \beta\) 使得 \(\alpha = \gamma \beta \delta\),则 \(\gamma A \delta\) 经过一步归约(reduce)到 \(\gamma \beta \delta\) 的逆过程。
记 \(\alpha \triangleleft \beta\) 表示 \(\alpha\) 可以一步归约到 \(\beta\)(即 \(\beta\) 通过一步推导得到 \(\alpha\))。
最左归约(Leftmost reduction):每步总是归约最左边的可归约子串。
NoteExample: Reductions
文法 \(G\):\(R \to S \mid T\),\(S \to aSb \mid ab\),\(T \to aTbb \mid abb\)
字符串 \(aaabbb\) 的最左归约:
\[aaabbb \triangleleft aaSbb \triangleleft aSb \triangleleft S \triangleleft R\]
字符串 \(aaabbbbbb\) 的最左归约:
\[aaabbbbbb \triangleleft aaTbbbb \triangleleft aTbb \triangleleft T \triangleleft R\]
Handles and Forced Handles
Definition: 在 CFG \(G\) 的最左归约过程中,每一步被归约的子串称为一个 handle(句柄)。
更精确地:给定 valid string \(\alpha\)(可以从 \(S\) 推导而来的句型),\(\alpha\) 的 handle 是指在最左归约中下一步要归约的子串及其对应的规则。
Forced handle:若 \(\alpha\) 的 handle 是唯一的(即不存在歧义),称之为 forced handle(强制句柄)。
Deterministic Context-Free Grammar (DCFG)
Definition: 一个 CFG \(G\) 是 DCFG(确定性上下文无关文法),当且仅当对 \(G\) 的每个 valid string,其 handle 都是 forced 的。
直觉:在 bottom-up parsing 过程中,每一步你都”被迫”只能做唯一的归约——没有选择的余地。
DK-Test
DK-test 是判断一个 CFG 是否为 DCFG 的算法。其核心思想是构造一个 DFA 来检测 handle 是否总是唯一的。
Step 1: 构造 NFA \(J\)(dotted rules)
对 \(G\) 的每条规则 \(A \to \alpha\),创建带点的项(dotted item)\(A \to \bullet\alpha, A \to a\bullet\beta, \ldots, A \to \alpha\bullet\)。
NFA \(J\) 的状态是所有 dotted items,转移由”移点”(shift dot)操作定义。
Step 2: 构造 NFA \(K\)
在 \(J\) 的基础上加入 \(\varepsilon\)-转移:若 \(A \to \alpha \bullet B \beta\) 是一个状态且 \(B \to \gamma\) 是一条规则,则加 \(\varepsilon\)-转移到 \(B \to \bullet\gamma\)。
Step 3: 子集构造得 DFA \(DK\)
对 NFA \(K\) 做标准的子集构造,得到 DFA \(DK\)。
DK-Test 条件:\(G\) 通过 DK-test 当且仅当 \(DK\) 的每个可达状态(状态集)中:
- 至多有一条”完成的”规则(即形如 \(A \to \alpha\bullet\) 的 item)
- 若存在完成的规则,则该状态中没有 item 的点后面是终结符
NoteExample: DK-Test
通过 DK-test 的文法:\(S \to Ta, T \to T(T) \mid \varepsilon\)
该文法的 DK 中,每个状态最多有一条完成规则,且不与 shift 冲突。所以它是 DCFG。
未通过 DK-test 的文法:\(S \to Ea, E \to E + T \mid T, T \to T \times a \mid a\)
在 DK 中存在某个状态同时包含 \(T \to a\bullet\) 和 \(T \to a \bullet\)(来自不同路径),导致 shift-reduce 冲突。所以它不是 DCFG。
Theorem: \(G\) 通过 DK-test \(\iff\) \(G\) 是 DCFG。
DCFG \(\Leftrightarrow\) DPDA(on Endmarked Languages)
Theorem: 对端标记语言 \(A\dashv\),\(A\dashv\) 由 DCFG 生成 \(\iff\) \(A\dashv\) 被 DPDA 识别。
NoteProof Sketch
DCFG \(\Rightarrow\) DPDA:由 DK-test 的 DFA \(DK\) 直接构造 DPDA。\(DK\) 的确定性保证了 parsing 过程中每步操作(shift 或 reduce)都是唯一确定的。具体来说,DPDA 维护一个状态栈,模拟 \(DK\) 的运行:
- Shift: 读入一个输入符号,压入 \(DK\) 的新状态
- Reduce: 根据完成规则弹出若干状态,然后根据 GOTO 表压入新状态
- 当读到端标记 \(\dashv\) 且栈中只剩初始状态时接受
DPDA \(\Rightarrow\) DCFG:给定识别 \(A\dashv\) 的 DPDA \(M\),构造等价的 DCFG。关键是将 DPDA 的配置转移翻译为 CFG 规则,同时保证生成的规则满足 DK-test(这利用了 DPDA 确定性转移的性质,保证 handle 的唯一性)。
Q.E.D.
Prefix-Free Languages
Definition: 语言 \(L\) 是 prefix-free(前缀无关) 的,若 \(L\) 中不存在两个不同的字符串 \(x, y\) 使得 \(x\) 是 \(y\) 的真前缀。
Lemma: 每个 DCFG 生成的语言都是 prefix-free 的。
这是 DCFG 的一个重要结构限制。端标记 \(\dashv\) 的引入正是为了绕过这一限制——\(A\dashv\) 总是 prefix-free 的(因为每个字符串都以 \(\dashv\) 结尾)。
graph TD
subgraph hierarchy["Language Hierarchy"]
subgraph CFL_box["Context-Free Languages (CFL)"]
subgraph DCFL_box["DCFL"]
subgraph RL_box["Regular Languages"]
end
end
end
end